
Foundation Model vs LLM: Which Model Fits Your Use Case?

Blog Summary:
This blog explores the key differences between foundation models and large language models (LLMs), providing insights into how each type operates and where they excel. Foundation models offer broad, multimodal flexibility, while LLMs are designed for deep language comprehension and generation. The comparison highlights differences in scope, training methods, applications, adaptability, and shared capabilities. Real-world examples illustrate how both model types are utilized in modern systems. By carefully evaluating these models, organizations can select the one that best aligns with their goals and supports scalable, future-proof solutions.
Artificial intelligence is reshaping how organizations build and scale intelligent applications, with foundation models and LLMs leading the charge. Foundation models are highly adaptable AI systems trained on vast, multimodal datasets, enabling them to work with text, images, audio, and more.
The global Large Language Model (LLM) market is projected to grow from USD 4.5 billion in 2023 to approximately USD 82.1 billion by 2033, expanding at a CAGR of 33.7% from 2024 to 2033.
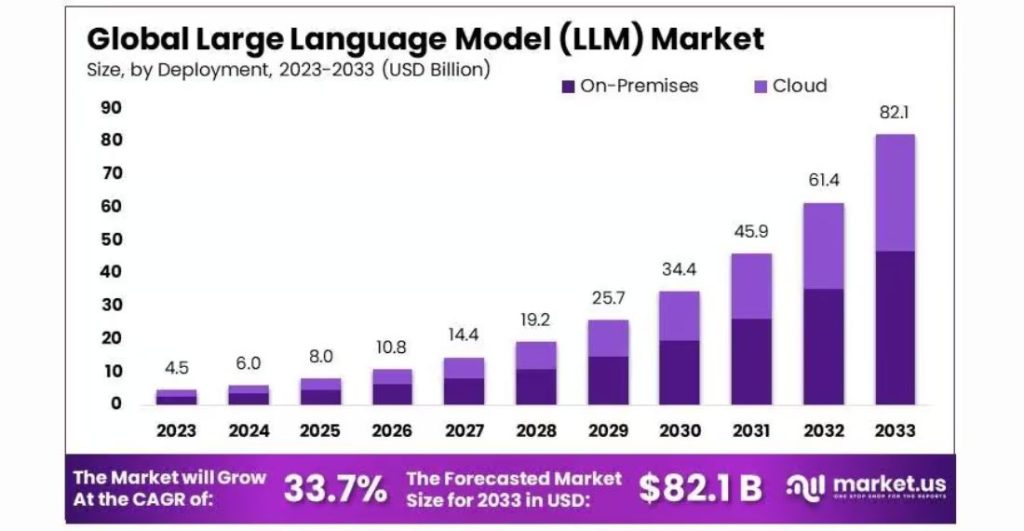
Understanding the differences between these models is crucial while selecting the best option for your project. In this blog, we’ll define each model, compare its capabilities and applications, explore real-world use cases, and much more to help you determine which approach is suitable for your needs. We’ll also dive into the “LLM vs foundational model” debate to provide a clearer perspective on their strengths and differences.
Understanding Foundation Models
Foundation models are large neural networks trained on vast, diverse datasets spanning text, images, audio, code, and other modalities. Their primary strength lies in the ability to learn generalized representations, enabling them to perform a wide range of tasks rather than being limited to a single function.
These models undergo extensive pretraining, where they absorb patterns, relationships, and context from billions of data points. This allows them to handle various tasks such as classification, translation, generation, reasoning, and retrieval without requiring full retraining for each new task.
A major advantage of foundation models is their adaptability. They can be fine-tuned or aligned with specific instructions to meet the needs of particular domains, enabling rapid development of specialized applications. Their versatility and scalability make them a crucial building block for modern intelligent systems.
Understanding Large Language Models (LLMs)
Large language models are advanced artificial intelligence systems designed to understand and generate human-like text. They are trained on massive collections of books, articles, and online content to learn patterns in language, grammar, context, and meaning.
Models such as GPT-4 and LLaMA use deep learning techniques to predict the next word in a sentence, enabling them to perform tasks like answering questions, writing content, summarizing text, and translating languages.
Large language models (LLMs) can be fine-tuned, instruction-tuned, or enhanced with domain-specific data to power applications in finance, healthcare, legal services, and education.
Their high accuracy in understanding and generating language makes them one of the most widely adopted components in modern intelligent systems—especially in scenarios where processing, analyzing, or generating text is central to the solution.
Foundation Model vs LLM: A Side-by-Side Snapshot
| Aspect | Foundation Model | LLM |
|---|---|---|
| Scope & Functionality | A broad AI model designed to serve as a base for multiple downstream tasks across domains. | A specialized type of foundation model focused on understanding and generating human language. |
| Training Data & Objectives | Trained on large, diverse, often multimodal datasets using self-supervised learning to learn general representations. | Trained primarily on massive text datasets with objectives like next-word prediction or masked language modeling. |
| Application Areas | Natural language processing, computer vision, speech recognition, robotics, multimodal AI systems. | Chatbots, content generation, translation, summarization, question answering, and coding assistance. |
| Specialization | General-purpose base model adaptable to many domains and tasks. | Language-focused specialization within the broader category of foundation models. |
| Adaptability and Fine-Tuning | Designed to be fine-tuned or adapted for various domain-specific tasks. | Fine-tuned for specific language tasks while remaining language-centric. |
Foundation Model vs LLM: A Detailed Comparison
With the rise of generative AI, the terms Foundation Models and Large Language Models (LLMs) are often used interchangeably. However, LLMs are a specialized type of foundation model focused primarily on language tasks.
Scope & Functionality
Foundation models are designed as broad, general-purpose systems. They operate across multiple data types, enabling them to generate representations and capabilities that support a wide range of downstream applications. In practice, they serve as a foundational layer, offering embeddings, multimodal understanding, and generative building blocks that other tools and systems can build upon.
Large language models, or LLMs, on the other hand, are more specialized. Their primary focus is on language, understanding, and generating human-readable text. They are particularly strong at tasks such as conversation, summarization, translation, and complex language-based reasoning. While foundation models emphasize cross-modal versatility, LLMs are optimized specifically for linguistic proficiency.
Training Data and Objectives
Foundation models are trained on intentionally diverse data. They are exposed to massive datasets spanning different content types, enabling them to learn broad statistical patterns across multiple modalities.
Their training objectives focus on learning transferable representations, often through self-supervised approaches. This allows a single pretrained model to be adapted efficiently for a wide range of downstream tasks.
LLMs are trained primarily on text-based corpora. Their objectives typically center on language modeling, such as predicting the next token, performing masked token prediction, or fine-tuning instructions. These objectives strengthen their ability to generate coherent and context-aware language. Because both their data and training goals are language-focused, they develop a detailed understanding of syntax, semantics, and disclosure.
Application Areas
Foundation models are well-suited to scenarios that require multimodal reasoning or a shared representation across tasks.
For instance, they enable use cases such as image captioning paired with retrieval, multimodal search, cross-domain transfer learning, and vision-language assistants. They are particularly valuable when a single backbone model can streamline development and reduce the engineering effort needed to support multiple applications.
LLMs, on the other hand, excel in text-centric tasks. Typical applications include customer support automation, document summarization, natural language–to–code generation, knowledge extraction, and conversational systems.
Because of their strong language fluency and ability to manage context effectively, LLMs are often the preferred choice when high-quality, coherent text output is essential.
Specialization
Foundation models are typically specialized through targeted fine-tuning or by adding adapter layers that guide the broadly trained model toward a specific domain, such as medical imaging combined with radiology reporting. Importantly, they can be adapted without losing their multimodal capabilities, which is beneficial when a use case requires more than language understanding alone.
LLMs specialize by narrowing their training or fine-tuning to domain-specific text corpora. This produces models that are highly proficient in the terminology, style, and conventions of a particular field, such as legal drafting, clinical documentation, or financial analysis, while continuing to operate primarily within the text modality.
Adaptability and Fine-Tuning
Foundation models are built with adaptability in mind. Techniques such as parameter-efficient fine-tuning, adapter modules, and prompt-based learning enable teams to reuse a single base model across multiple tasks without retraining it from scratch. This approach lowers costs and accelerates deployment, especially when supporting several related applications.
LLMs are also adaptable, but their optimization is typically centered on language performance. Methods such as instruction tuning, few-shot prompting, and domain-specific fine-tuning are refined for targeted language tasks.
In practice, the distinction lies in scope: adapting an LLM primarily enhances linguistic output, whereas adapting a foundation model can extend or rebalance capabilities across modalities and languages.
Scalability and Infrastructure Needs
Both foundation models and LLMs are resource-intensive, but the scale and infrastructure required can differ. Foundation models, due to their multimodal nature and broader scope, typically demand more computational power for both training and deployment. These models often require large-scale hardware infrastructure and sophisticated systems to handle the diverse data types they process.
LLMs, while still requiring significant computational resources, can sometimes be easier to scale because of their more focused application to text processing. They are typically optimized for high-performance natural language tasks, and once trained, they are often more straightforward to deploy and fine-tune for specific use cases.
However, the infrastructure needs for training and fine-tuning LLMs can still be demanding, particularly when they are customized for specialized tasks.
Security and Risk Considerations
Both foundation models and LLMs face critical security and ethical concerns, though the nature of these risks can differ. Foundation models, being multimodal, may inadvertently generate harmful or biased content not only in text but also in images, audio, or video. Managing this complexity requires robust safeguards to prevent unintended outputs.
LLMs focusing on text are more vulnerable to adversarial inputs, where manipulated prompts could lead to undesired responses. Both types of models require constant monitoring, fine-tuning, and mechanisms such as content filtering, bias detection, and oversight to mitigate risks of unsafe, biased, or harmful outputs.
Performance and Output Capabilities
Foundation models excel in versatility, handling a range of tasks that span multiple domains and modalities. They can generate text from images, perform cross-modal reasoning, or even create multimedia outputs. However, this broad capability may result in slightly less specialization than models focused on a single modality.
LLMs, on the other hand, are optimized for text-based tasks such as summarization, conversation, translation, and content generation. Their performance in language generation is typically superior, as they are trained specifically for such tasks. While LLMs are powerful within their linguistic domain, they cannot handle multimodal tasks as efficiently as foundation models.
Multimodal Capabilities
Foundation models are designed for multimodal tasks, meaning they can process and generate outputs across data types. This makes them highly effective for applications that require cross-domain understanding, such as visual question answering, text-to-image generation, and multimodal search. Their ability to integrate multiple modalities makes them flexible for a wide variety of use cases.
LLMs, while capable of handling limited multimodal inputs (such as GPT-4’s text-and-image understanding), are primarily text-based and lack the breadth of multimodal capabilities. Therefore, for tasks that involve complex reasoning across data types, foundation models are generally the better choice.
Customization Complexity
Customizing foundation models can be more challenging due to their broad scope and multimodal architecture. Fine-tuning them for specific domains often requires significant adjustments, such as adding specialized layers or domain-specific datasets, which may impact their performance across modalities. The need to maintain a balance between generalization and specificity adds complexity to the process.
LLMs, in contrast, are easier to adapt to specific domains because they primarily focus on language. Fine-tuning them for specialized tasks typically involves training on domain-specific text, making the customization process simpler and quicker. However, this simplicity comes at the cost of multimodal capabilities, limiting their use in some scenarios.
Where Do Foundation Models and LLMs Overlap?
Although foundation models and LLMs are designed for different scopes, they are built on many of the same core principles that shape their function and evolution. Their similarities become more evident when examining their underlying architectures, training methods, and scaling strategies:
Underlying Model Architectures
Both foundation models (FMs) and large language models (LLMs) are built on transformer architectures introduced in Attention Is All You Need.
LLMs such as GPT-4 and BERT are specialized foundation models focused on language.
Overlap: Same core architecture; different scope (general vs language-focused).
Training Techniques & Approaches
Both use self-supervised pretraining, large-scale datasets, fine-tuning, and techniques like RLHF (e.g., ChatGPT).
Overlap: Shared large-scale pretraining followed by task-specific adaptation.
Computational Requirements & Scaling
Both require massive datasets, distributed GPU/TPU infrastructure, and follow scaling laws highlighted by OpenAI.
Overlap: Performance improves as parameters, data, and compute increase.
Contribution to Generative Technologies
Foundation models power generative AI across domains, including image models like DALL·E, while LLMs generate text, code, and conversations.
Overlap: Both enable generative technologies by modeling complex data patterns.
Ability to Understand Context & Meaning
Both rely on attention mechanisms to capture context and meaning across inputs.
Overlap: LLMs apply this to language; other foundation models extend it to multimodal data.
Popular Foundation Model Examples
To better understand the distinction between foundation models and LLMs, examining real-world examples of foundation models can be useful. These models are built as large, adaptable AI systems that can be fine-tuned for tasks across language, vision, and other domains.
Below are three notable foundation models that showcase this versatility:
BERT
BERT, developed by Google in 2018, is a foundational breakthrough in natural language processing. It uses a bidirectional transformer architecture to understand context from both directions in a sentence, significantly improving language comprehension.
Pre-trained on large text datasets, BERT can be fine-tuned for tasks like sentiment analysis, question answering, and search optimization. As a foundation model, it serves as a strong base for various language-driven enterprise applications.
Mistral
Mistral is a family of high-performance open-weight models developed by Mistral AI. Known for efficiency and strong reasoning capabilities, these models can be fine-tuned for applications such as content generation, coding assistance, and enterprise automation.
Their flexible deployment options, including private and on-premise environments, make them a practical example of adaptable LLM foundation models in real-world business settings.
DALL-E
DALL·E, created by OpenAI, is a multimodal foundation model that generates images from text prompts. By learning the relationship between language and visual concepts can produce realistic or creative images for marketing, design, and content creation. DALL·E clearly illustrates how foundation models extend beyond text, distinguishing them from language-focused LLMs in the foundation-models discussion.
Popular LLM Examples
A number of prominent large language models showcase the capabilities of modern language-based AI. The following examples illustrate how LLMs are applied in real-world systems and platforms.
OpenAI’s GPT-4
GPT-4 is a highly advanced large language model known for its strong reasoning, contextual understanding, and natural text generation. It supports tasks such as content creation, summarization, translation, coding, and conversational AI. Widely used in enterprise applications and tools like ChatGPT, GPT-4 is a leading example in the foundation model vs LLM discussion for text-focused AI solutions.
Google’s PaLM
PaLM (Pathways Language Model) is Google’s large-scale LLM built for multilingual understanding and advanced reasoning. It performs well in knowledge-based Q&A, logical problem-solving, and translation, and is integrated into various AI-powered tools within Google’s ecosystem.
LLama
LLaMA is a family of open-weight large language models developed by Meta. Known for flexibility and customization, it allows researchers and enterprises to fine-tune models for domain-specific applications, making it a strong example of adaptable LLM foundation models.
Foundation Model vs LLM: Deciding What Works for You
Deciding between a foundation model and a large language model (LLM) boils down to the type of tasks you’re tackling, the complexity of your requirements, and how specialized or versatile your system needs to be.
When Should You Opt for a Foundation Model?
A foundation model is best when your tasks involve a variety of data types, whether that’s text, images, audio, or structured data. It’s an ideal choice for multimodal workflows, applications that span different domains, or situations where you need a single model to handle a range of tasks. Foundation models are highly adaptable and scalable, making them a great option when you need broad capabilities for many use cases.
When Should You Pick a Large Language Model?
Opt for an LLM when your primary focus is tasks related to language, such as conversation, summarization, content generation, translation, classification, or text analysis. LLMs shine in scenarios where high linguistic accuracy and deep contextual understanding are critical. If your work revolves primarily around text and you need precision, an LLM is likely your best option for efficiency and performance.
How BigDataCentric Supports Your Model Selection & Deployment?
BigDataCentric streamlines model selection by combining domain expertise, data engineering best practices, and advanced analytics frameworks to identify the most suitable algorithms for your specific business problem. Our team evaluates data quality, volume, velocity, and variety to determine whether traditional machine learning models, deep learning architectures, or hybrid approaches are the best fit.
By leveraging platforms such as Apache Spark and TensorFlow, we ensure scalable experimentation, performance benchmarking, and hyperparameter tuning. This structured evaluation process reduces risk, improves accuracy, and ensures that selected models align with both technical requirements and strategic business goals.
For deployment, we focus on building production-ready pipelines that integrate seamlessly into your existing ecosystem. Using containerization technologies like Docker and orchestration tools such as Kubernetes, we enable secure, scalable, and automated model deployment across cloud or on-premise environments.
Continuous monitoring, version control, and performance tracking are integrated into the workflow to ensure long-term model reliability. This end-to-end approach guarantees that your AI solutions transition from experimentation to tangible, real-world business impact.
In the context of model selection, we also evaluate options like “large language models vs foundation models” to ensure you’re adopting the right approach for your specific use case.
Conclusion
Understanding the difference between foundation models and large language models is crucial for organizations in selecting the appropriate approach based on their objectives, whether they require broad multimodal capabilities or highly specialized language performance.
Each model type offers distinct advantages, and the choice ultimately hinges on the nature of the data and the desired level of adaptability or specialization.
As the field continues to evolve, both foundation models and LLMs will remain pivotal in driving advanced applications. By adopting the right strategy, businesses can harness these technologies to create scalable, efficient, and high-performing solutions that foster long-term digital growth.
FAQs
-
Does an LLM fall into the foundation model category?
Yes, LLMs are a type of foundation model because they are trained on large-scale, diverse data and can be adapted for many downstream tasks, such as translation, Q&A, summarization, and coding. Not all foundation models are LLMs, but most modern LLMs qualify as foundation models.
-
Is ChatGPT a foundation model?
ChatGPT is not itself a foundation model. It is an application built on top of a foundation model such as GPT-4. The underlying GPT models are foundation models; ChatGPT is the user-facing system powered by them.
-
Is LLM replacing NLP?
No. LLMs are part of Natural Language Processing (NLP), not a replacement for it. NLP is the broader field covering all techniques for processing language. LLMs are a powerful modern approach within NLP, but rule-based systems, statistical models, and smaller task-specific models still have roles.
-
Why are large language models called foundation models?
They are called foundation models because they serve as a base (foundation) for many applications. Trained on massive datasets, they can be fine-tuned or prompted to perform diverse tasks across industries, forming the core layer for specialized AI systems.
-
Is LLM the same as generative AI?
No. LLMs are a subset of generative AI focused on text generation and understanding. Generative AI is broader and includes image, audio, video, and code generation models. For instance, image generators and music models are generative AI systems but not LLMs.

Jayanti Katariya is the CEO of BigDataCentric, a leading provider of AI, machine learning, data science, and business intelligence solutions. With 18+ years of industry experience, he has been at the forefront of helping businesses unlock growth through data-driven insights. Passionate about developing creative technology solutions from a young age, he pursued an engineering degree to further this interest. Under his leadership, BigDataCentric delivers tailored AI and analytics solutions to optimize business processes. His expertise drives innovation in data science, enabling organizations to make smarter, data-backed decisions.




