
How Is Inference in Machine Learning Changing Modern Industries?

Blog Summary:
This blog explores the concept of inference in machine learning, highlighting its importance, how it differs from training, and where it’s applied in real-world scenarios. It covers key processes like the forward pass, output prediction, and deployment environments. You’ll also discover major challenges in inference implementation and how businesses can overcome them. Practical use cases across industries further illustrate its growing impact.
In recent years, machine learning (ML) has revolutionized the way businesses operate, transforming raw data into valuable insights and enabling automation across industries. While most discussions around ML focus on model training and algorithm selection, a critical phase often underrepresented is inference in machine learning. This stage marks the real-world application of a trained model — where it makes predictions based on unseen data.
Whether you’re diagnosing diseases, powering recommendation engines, or detecting fraudulent transactions, inference is the part of the pipeline that directly impacts users. Without it, even the most accurate model remains just an academic artifact. Inference is where models become functional tools — transforming predictions into decisions, and data into action.
As machine learning systems continue to scale in complexity and deployment, understanding machine learning inference becomes increasingly vital. This article explores how inference works, why it’s essential, how it differs from training, and where it’s being applied today — while also addressing the challenges and considerations surrounding real-world implementation.
Introduction to Machine Learning Inference
Machine learning inference is the phase where a trained model is deployed to make predictions on new, unseen data. Unlike the training phase, which focuses on learning patterns from labeled datasets, inference is all about applying that learned knowledge to perform real-time decision-making or classification tasks.
Think of training as a student preparing for an exam by studying various topics. Inference is the actual exam — the student applies what they’ve learned to answer new questions. In a similar way, an inference model in machine learning takes in fresh input data and outputs predictions based on the patterns it has previously learned.
Inference can occur in a variety of environments:
- Cloud-based inference, which is highly scalable and commonly used for batch predictions.
- Edge inference, where predictions are made directly on user devices or IoT systems, enabling low-latency, offline functionality.
Depending on the use case, the deployment strategy for ML inference can impact speed, scalability, and cost-efficiency. Whether it’s powering real-time recommendations or automating image classification in autonomous vehicles, the ml model inference phase is where business value is truly delivered.
Ready to Operationalize Your Machine Learning Models?
Use inference in machine learning to turn trained models into real-time business solutions that drive action, insights, and impact across industries.
The Importance of Inference in Machine Learning
While model training is the foundational stage of any machine learning pipeline, it’s during inference that these models begin to demonstrate tangible value. Inference in machine learning is the phase that brings predictive models to life — allowing businesses, devices, or applications to use trained intelligence in real-world scenarios.
Without inference, all the effort spent on data collection, cleaning, feature engineering, and model optimization remains theoretical. For example, a healthcare ML system trained to detect early signs of diabetic retinopathy only becomes valuable once it can infer a diagnosis from a patient’s new eye scan. Similarly, in a fraud detection system, ml model inference is what enables immediate alerts when unusual transaction behavior is detected.
Another reason inference is critical is that it often operates in real-time or near real-time. This means predictions need to be both accurate and fast. In sectors like autonomous driving or financial trading, even a delay of milliseconds could lead to critical failures or missed opportunities.
Moreover, modern applications increasingly require continuous inference — not just one-time predictions. Systems must constantly ingest live data and provide dynamic responses. For businesses, this translates into more responsive customer experiences, enhanced operational efficiency, and better decision-making.
You Might Also Like:
How Does AI Inference in Machine Learning Work?
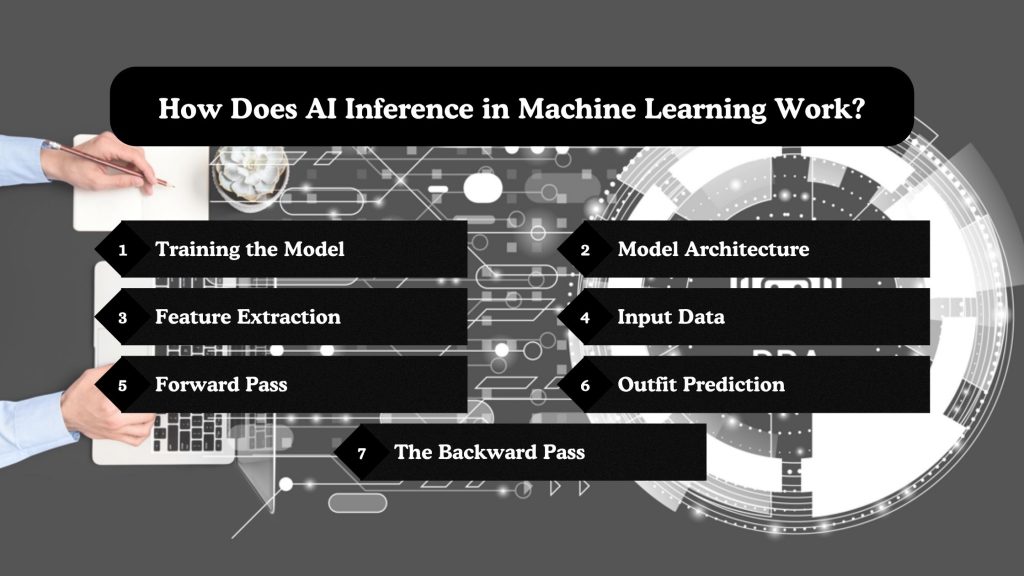
Understanding how inference in machine learning works requires breaking down the key steps that happen after a model has been trained. Once the training is complete, the model is frozen — meaning its weights and parameters are fixed. It’s then deployed in a production environment to process new data and deliver predictions. Here’s how this flow typically looks:
Training the model
Before inference begins, a model must go through training using historical, labeled data. During this phase, the model learns patterns and relationships between features and target outcomes. The better the training phase, the more accurate and generalizable the inference results will be. Although training is resource-intensive and time-consuming, it sets the foundation for successful ml model inference.
Model Architecture
The architecture refers to the structure of the neural network or algorithm used — whether it’s a decision tree, CNN, transformer, or ensemble method. The chosen architecture impacts how well the model performs during inference. For example, deep neural networks often offer higher accuracy but can be computationally expensive during prediction, especially in edge environments.
Feature Extraction
Feature extraction involves selecting and transforming relevant data inputs for the model. In production, features must be generated in the same way as during training to maintain consistency. Any discrepancy here can degrade the performance of the inference model machine learning setup.
Input Data
During inference, new data (which the model hasn’t seen before) is fed into the system. This could be an image, text, a time-series stream, or tabular data depending on the use case. Ensuring that the input format matches what the model expects is essential to prevent misclassification or errors.
Forward Pass
This is the actual computation where the input data passes through the model’s layers (weights and biases) to generate an output. No learning or updating happens here. The forward pass is the core step in machine learning inference — where the prediction is calculated from the trained model parameters.
Output Prediction
The final prediction is generated — whether it’s a classification label, regression value, or probability score. For instance, a sentiment analysis model might output “positive” or “negative,” while a pricing model may return a numerical value.
The Backward Pass
While the backward pass is primarily a training concept (where gradients are calculated and weights are updated), it’s worth noting here to contrast with inference. During inference, the backward pass is skipped entirely. This is why inference requires less compute power than training and is often optimized for speed and scalability.
Machine Learning Inference vs Training
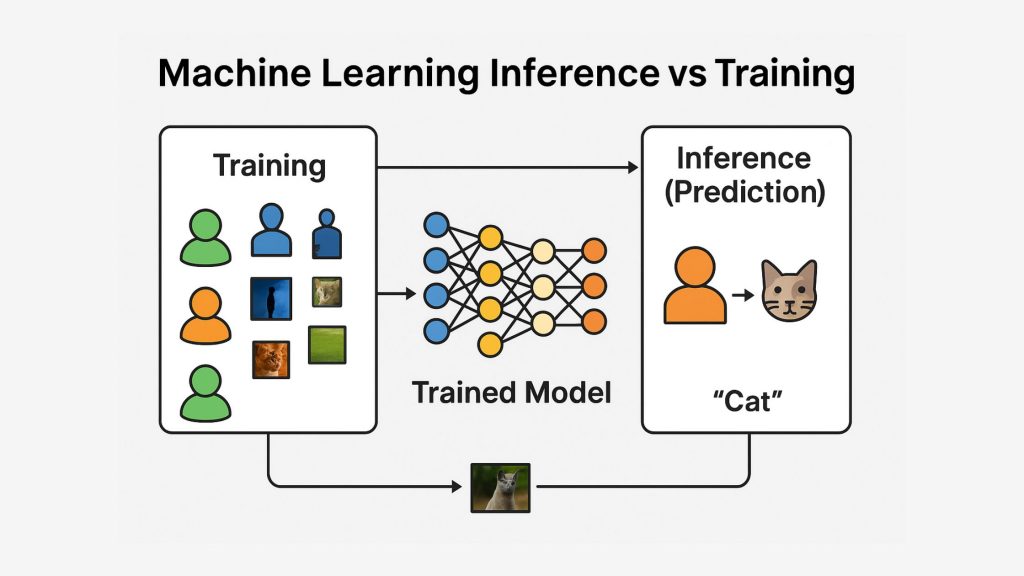
Understanding the distinction between machine learning inference and training is crucial for developing efficient ML systems. While they are two sides of the same coin, they differ significantly in purpose, resource requirements, and execution strategy.
| Aspect | Training | Inference |
|---|---|---|
| Goal | Learn patterns from labeled data | Make predictions on new, unseen data |
| Computational Load | High — requires intensive GPU/CPU processing | Low — optimized for fast response and minimal latency |
| Frequency | Done occasionally during model updates | Occurs continuously in production |
| Data Requirements | Labeled datasets | Unlabeled, real-world data |
| Resource Usage | Involves large-scale compute clusters and memory | Can run on lightweight or edge devices |
| Process | Includes both forward and backward pass | Only forward pass is executed |
Key Considerations when Choosing Between Inference and Training
Choosing between model training and inference isn’t just a technical decision — it’s a strategic one. Various factors such as performance expectations, infrastructure, team skills, and business timelines play a critical role in determining the right focus.
Time to Market
Training a model can take days or even weeks, especially when dealing with large datasets and deep neural networks. In contrast, inference needs to be instantaneous or near real-time, especially for use cases like fraud detection or self-driving cars. For businesses aiming for quicker deployments, focusing on optimizing the ml inference vs training trade-off is critical.
Model Performance
A highly accurate model during training doesn’t guarantee the same level of performance during inference. Differences in data quality, feature engineering, or runtime environments can cause performance drift. That’s why monitoring inference in machine learning in production is as important as evaluating metrics during training.
Resources, Constraints, or Development Cost
Training often requires powerful hardware and considerable development costs. Inference, on the other hand, should be lean and cost-efficient — especially when deployed at scale. Whether you’re doing inference on the cloud, edge devices, or mobile apps, cost becomes a deciding factor.
Team Expertise
Building and training models requires data science and ML engineering skills. However, implementing efficient ml model inference also needs expertise in DevOps, model serving frameworks, and infrastructure management. Companies often split responsibilities between research and deployment teams for this reason.
Need Help Choosing Between Training and Inference?
Connect with BigDataCentric to streamline your ML lifecycle — from model development to scalable inference deployment that drives real-time results.
Real-world Applications of Machine Learning Inference
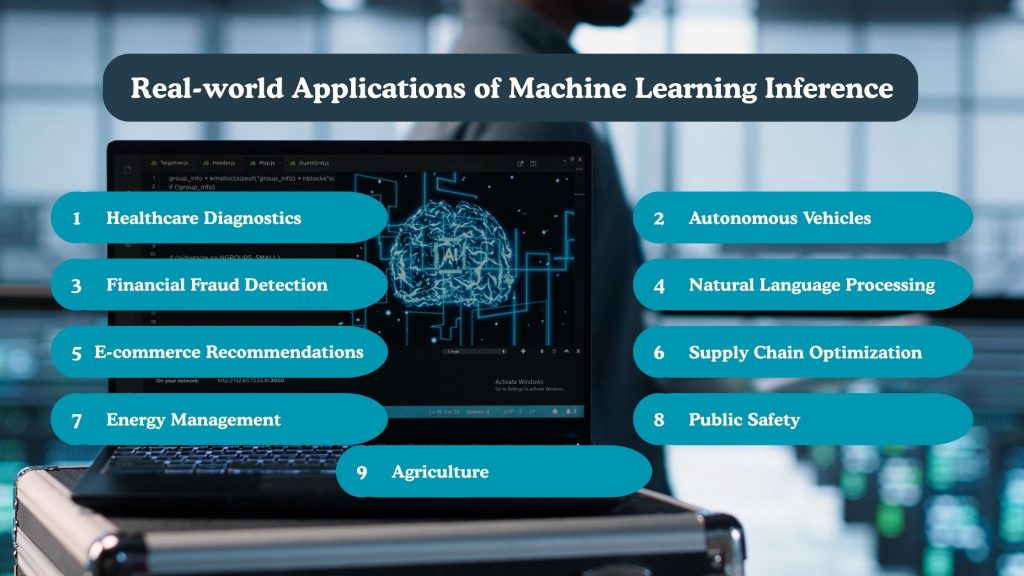
The real power of inference in machine learning is realized through its application across industries. Whether embedded in everyday apps or powering mission-critical systems, inference allows businesses to make fast, intelligent decisions at scale. Below are some impactful real-world use cases where ml model inference plays a vital role:
Healthcare Diagnostics
Inference is used to detect diseases from medical images, predict patient outcomes, and assist in diagnostics. Once a model is trained using historical health records and scans, inference enables real-time diagnosis support — such as identifying pneumonia in chest X-rays or early signs of cancer in MRIs. For example, AI-assisted tools can now provide results faster than traditional radiology, allowing timely interventions.
Explore more in our detailed blog on Chatbots in Healthcare.
Autonomous Vehicles
Self-driving cars rely heavily on inference to make split-second decisions. From detecting pedestrians to recognizing traffic signs, models perform constant inference on video feeds and sensor data. Speed, accuracy, and reliability of inference model machine learning systems are crucial here to ensure safety and efficiency in navigation.
Financial Fraud Detection
Banks and fintech platforms use machine learning inference to spot anomalies in transaction behavior. Inference models process real-time data streams to flag suspicious activity, helping prevent fraud before it occurs. Unlike training, which is periodic, inference runs continuously to ensure 24/7 monitoring and protection.
Natural Language Processing (NLP)
From smart assistants to chatbots, NLP-driven systems use inference to interpret, respond, and generate human-like conversations. Trained language models can summarize documents, translate languages, and answer customer queries — all happening via fast, low-latency inference.
Explore Our Service
Natural Language Processing (NLP) Services and Custom Solutions
E-commerce Recommendations
Inference helps e-commerce platforms personalize user experiences by suggesting products based on browsing history, preferences, and past purchases. Recommender systems use ml inference vs training patterns to continuously adapt to user behavior in real time, improving conversion rates and customer satisfaction.
Supply Chain Optimization
Predictive maintenance, demand forecasting, and route optimization are powered by real-time inference from IoT and logistics data. For instance, a trained model can infer delivery delays or stockouts and help companies adjust inventory or transport schedules dynamically.
Energy Management
Smart grids and smart meters utilize machine learning inference to predict energy consumption, detect outages, and suggest efficient usage patterns. Inference enables utility companies to make data-driven adjustments on the fly, improving energy distribution and reducing waste.
Public Safety
Inference models are increasingly used in surveillance systems, emergency response, and crime prediction. For example, CCTV footage can be analyzed in real time to detect unusual activities or identify missing persons using facial recognition.
Agriculture
Inference models play a crucial role in ML in agriculture, aiding farmers with crop disease detection, yield prediction, and soil monitoring. Drones equipped with cameras and sensors capture data, which is then analyzed using inference models to deliver real-time insights — enabling better decision-making and increased efficiency on the field.
Challenges in Implementing Inference in Machine Learning
While inference in machine learning unlocks powerful real-time capabilities, it also brings a unique set of challenges. From data quality to infrastructure and model transparency, deploying ML models at scale isn’t always straightforward. Below are some of the most pressing hurdles organizations face during ml model inference implementation:
Large Quality Data
High-quality training data is essential, but inference also relies on consistently structured, clean input data. In many real-world applications, incoming data may be noisy, incomplete, or unstructured — causing the model to make inaccurate predictions. Maintaining data pipelines that mirror training data preprocessing is critical to inference accuracy.
Interpretability
Many models used in production — especially deep learning architectures — are often considered “black boxes.” When these models generate predictions during inference, it’s challenging for stakeholders to understand why a decision was made. This lack of transparency can be problematic in regulated industries like finance or healthcare, where explainability is as important as accuracy.
Confounding Variables
If the model encounters data distributions during inference that differ from training data — due to seasonality, user behavior shifts, or market changes — performance can degrade. These hidden or confounding variables may lead to bias or misleading predictions. Continuous monitoring and retraining are required to ensure the inference model machine learning remains reliable and relevant.
In addition to technical challenges, organizations must also consider cost, latency, and compliance issues. Choosing between cloud inference and edge deployment, for instance, affects scalability, privacy, and user experience.
Still Facing Challenges with ML Inference Deployment?
Overcome data, scalability, and model transparency issues with BigDataCentric’s expert ML consulting and end-to-end deployment solutions.
Conclusion
As machine learning matures and finds its way into real-world systems, the spotlight is shifting from just building models to deploying them effectively. Inference in machine learning is no longer an afterthought — it is the gateway to delivering intelligent, data-driven services at scale.
Whether it’s diagnosing patients, detecting fraud, or optimizing supply chains, inference is the bridge between predictive potential and real-time impact. However, deploying machine learning inference comes with challenges — from ensuring data consistency to choosing the right infrastructure and keeping models interpretable and performant over time.
At BigDataCentric, we help businesses unlock the full power of machine learning by not just building robust models but also ensuring they’re production-ready. Our team specializes in delivering end-to-end solutions — from model training to scalable ml model inference pipelines — tailored to your domain and goals.
If you’re looking to move beyond experimentation and into actionable AI deployment, our expertise in AI, ML, and model inference can help you get there faster, smarter, and with lasting impact.
Explore our full range of Machine Learning Development Services to see how we can support your next project.
FAQs
-
What are the types of inference?
The main types of inference are batch inference, real-time (online) inference, and edge inference. Batch processes large data sets at once, real-time delivers instant predictions, and edge inference runs models directly on local devices for low-latency responses.
-
How can machine learning inference be improved?
Inference can be improved by optimizing the model architecture, using techniques like quantization or pruning, deploying with faster frameworks (e.g., TensorRT, ONNX), and leveraging hardware acceleration (e.g., GPUs or TPUs) for faster predictions.
-
What role does inference play in MLOps pipelines?
Inference is the final stage of the MLOps lifecycle where trained models are deployed to serve predictions. It's monitored for performance, drift, and accuracy, enabling continuous feedback loops and retraining when necessary.
-
How is inference handled in deep learning models?
In deep learning, inference involves running the forward pass of a trained neural network on new input data. It uses fixed weights to generate outputs without updating the model and can be accelerated with GPUs for real-time predictions.
-
Does ML inference require GPU?
Not always. While GPUs speed up inference for large or complex models, many use cases can run efficiently on CPUs, especially for small models or edge devices. The need depends on latency requirements and model complexity.

Jayanti Katariya is the CEO of BigDataCentric, a leading provider of AI, machine learning, data science, and business intelligence solutions. With 18+ years of industry experience, he has been at the forefront of helping businesses unlock growth through data-driven insights. Passionate about developing creative technology solutions from a young age, he pursued an engineering degree to further this interest. Under his leadership, BigDataCentric delivers tailored AI and analytics solutions to optimize business processes. His expertise drives innovation in data science, enabling organizations to make smarter, data-backed decisions.




