
Named Entity Recognition: Key Uses & Benefits
Blog Summary:
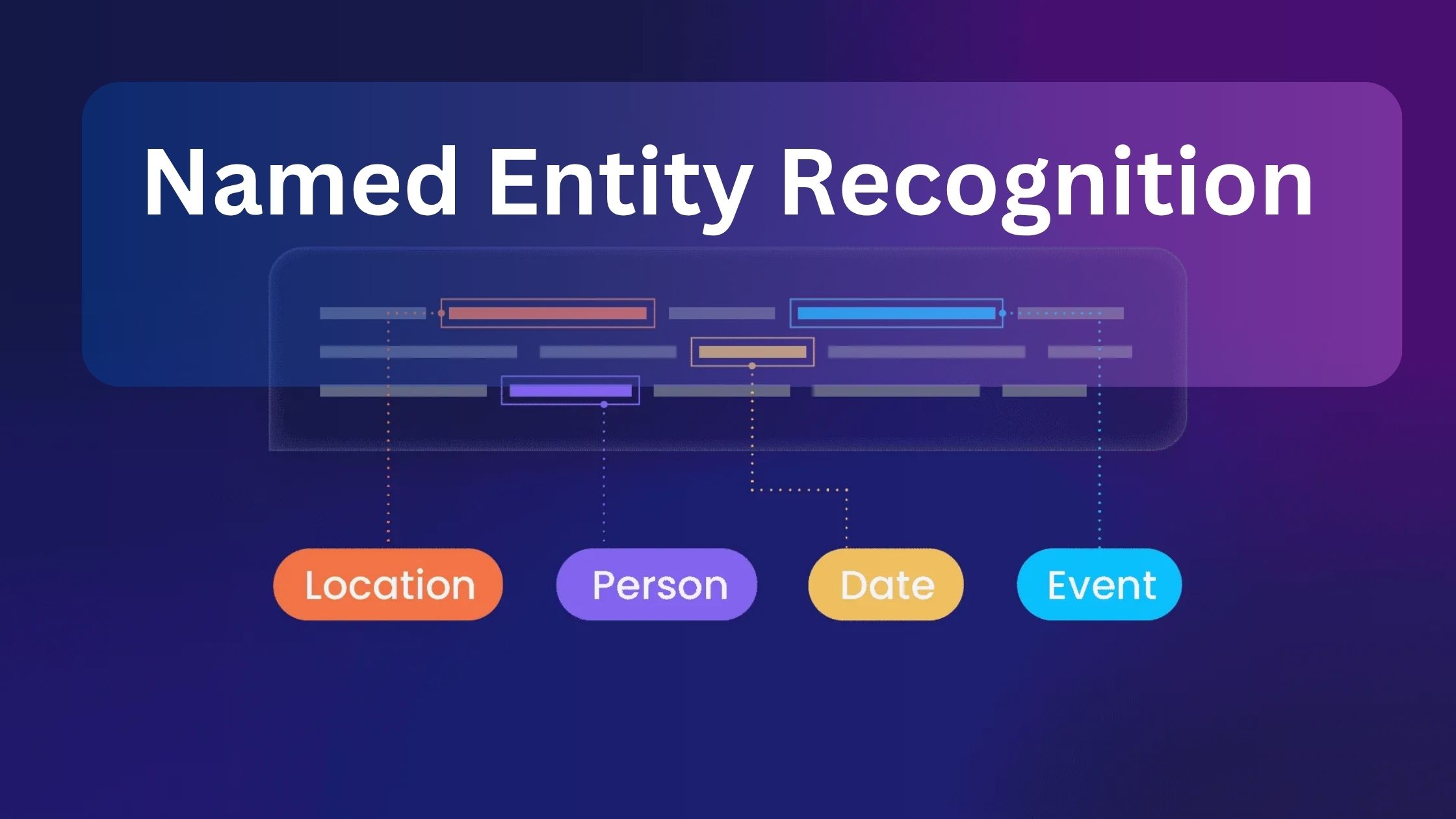
In this blog, we explore the concept and practical applications of Named Entity Recognition (NER)—a fundamental technique in natural language processing. From understanding how NER works to the different types of systems powering it, you’ll gain clarity on how entities are extracted and categorized from raw text. We’ll also examine core components like tokenization, classification, and contextual analysis. Finally, the blog covers real-world use cases, the benefits of using NER across industries, and its promising future.
With the growing volume of unstructured data, particularly textual content, businesses and researchers are seeking more effective ways to extract meaningful information. This is where Named Entity Recognition (NER) becomes indispensable. NER is a powerful technique under the umbrella of natural language processing (NLP) that identifies and categorizes key information — such as names of people, organizations, locations, dates, and other relevant details — from unstructured text data.
Imagine sifting through thousands of customer reviews, news articles, or emails to manually extract product names, user complaints, or event locations. This would be time-consuming, error-prone, and inefficient. NER automates this process, allowing systems to understand language at a granular level by recognizing entities and their context.
NER is not just a tool for data scientists — it’s now a common component in search engines, virtual assistants, chatbots, recommendation systems, and many enterprise applications. Whether you’re working in healthcare, finance, law, or ecommerce, the ability to extract structured data from text adds immense value to decision-making and automation efforts.
Understanding Named Entity Recognition
Named Entity Recognition is a crucial step in natural language processing services that focuses on identifying specific pieces of information in a text, such as company names, places, or product names, and understanding their significance within the context. Rather than treating all words equally, NER helps machines recognize terms that refer to real-world objects or concepts.
For example, if a sentence mentions a well-known company planning a product launch in a major city on a specific date, a NER system can detect each of these elements as distinct and important. This ability allows it to transform free-flowing text into structured information that software systems can understand and analyze.
NER operates behind the scenes in various applications, such as automatically tagging locations in news articles, highlighting person names in legal documents, or extracting product mentions from customer reviews. By doing so, it becomes easier to sort, search, and summarize vast amounts of content quickly and accurately.
What makes NER valuable is not just its ability to detect individual words, but to understand their meaning based on context. It ensures that a company name isn’t confused with a person’s name or a product’s name with a location. This context-aware recognition enhances the intelligence of data pipelines and enhances how systems interpret text.
How Does Named Entity Recognition Work?
The functioning of Named Entity Recognition involves a multi-step process that transforms raw, unstructured text into structured data by detecting and classifying entities. It begins with preprocessing the input text — cleaning it up by removing noise, such as punctuation, correcting misspellings, and converting all characters to lowercase.
Once cleaned, the text is tokenized, meaning it’s broken down into smaller units, usually words, which makes it easier to analyze each segment individually.
After tokenization, the system applies part-of-speech tagging to assign grammatical roles to each word, helping to understand sentence structure and meaning. The real challenge lies in identifying which groups of words are potential entities — this could be a person’s name, a location, or a product mentioned within the text.
Once these spans of text are identified, the next step is to categorize them into appropriate categories based on the use case.
Modern NER systems take it a step further by utilizing surrounding context to interpret meaning more accurately. For instance, recognizing whether “Apple” refers to a fruit or a tech company depends entirely on the words around it. Context-aware models, particularly those powered by deep learning, handle this nuance far more effectively than traditional rule-based systems.
Overall, NER systems rely on a combination of linguistic rules, statistical models, or machine learning algorithms to ensure high-quality entity recognition. The final output is structured and categorized data that can be utilized across various search engines, recommendation engines, analytics tools, and other applications.
Different Types of NER Systems
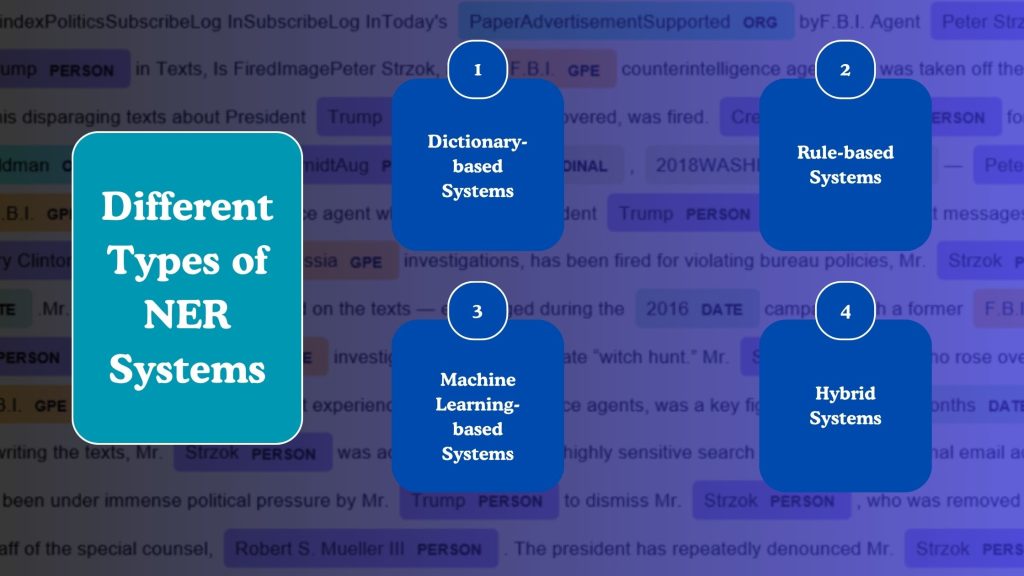
Named Entity Recognition systems have evolved, and today they come in various forms — each with its strengths and trade-offs. The choice of an NER system often depends on the complexity of the text, the domain of application, and the desired level of accuracy.
Let’s take a closer look at the major types of NER systems used today.
Dictionary-based Systems
Dictionary-based NER systems rely on predefined lists or lexicons of known entities. These dictionaries may contain names of people, cities, products, or organizations, and the system matches input text against this reference. This approach is straightforward and fast, making it suitable for limited-scope tasks or static datasets.
However, it lacks flexibility and fails when encountering new or misspelled entity names. For example, in rapidly changing industries like tech or entertainment, new product names or celebrity mentions may not be present in the dictionary, resulting in missed entities.
Rule-based Systems
Rule-based NER systems utilize handcrafted rules developed by linguists or domain experts. These rules define patterns using grammar, context, or specific language structures, such as recognizing a capitalized word following “Mr.” as a person’s name.
This method offers better control and precision than dictionary-based systems, particularly in domains with strict formats, such as legal or scientific documents. However, it can become challenging to scale or maintain, as language usage varies significantly across different texts and industries.
Machine Learning-based Systems
Machine learning-based NER systems use algorithms that learn patterns from annotated training data. These machine learning models, such as Conditional Random Fields (CRFs), Hidden Markov Models (HMMs), or modern deep learning approaches like BiLSTM-CRF and Transformer-based architectures (e.g., BERT), can identify entities by recognizing linguistic features and contextual patterns.
These systems are more adaptable, accurate, and scalable than rule- or dictionary-based approaches. They improve over time with more data but require significant labeled datasets and computational power to train effectively.
Hybrid Systems
Hybrid NER systems combine two or more of the above approaches to strike a balance between flexibility, performance, and ease of implementation. For instance, a system might start by using dictionaries for quick matches, then apply machine learning to verify or refine those results, while also falling back on rules to catch edge cases. This blended strategy makes hybrid systems particularly useful in enterprise environments where accuracy and adaptability are both critical.
Each of these system types serves different goals. Simpler use cases may get by with rule-based or dictionary methods, while industries dealing with varied and complex language—such as healthcare, finance, or legal—benefit greatly from machine learning and hybrid approaches.
You Might Also Like
Key Concepts of Named Entity Recognition (NER)
To fully understand how Named Entity Recognition functions under the hood, it’s essential to grasp the key building blocks that comprise its process. These concepts work together to ensure entities are accurately extracted, interpreted, and categorized from text. Let’s break down each of these components:
Tokenization
Tokenization is the process of breaking down raw text into smaller units, known as tokens. These tokens are typically words or phrases, serving as the foundation for further linguistic analysis. Without tokenization, a system would struggle to understand sentence boundaries or the relationships between different terms.
For example, the sentence “BigDataCentric offers AI-driven solutions” would be split into separate tokens to analyze the structure and identify potential entities.
Entity Identification
Once the text is tokenized, the next step is to identify which tokens or combinations of tokens might be entities. This could involve detecting patterns in how entities are typically formatted, such as capitalized words or recurring names in the context.
In modern systems, entity identification extends beyond surface-level cues. It utilizes context to determine entity boundaries, particularly for longer or multi-word entities, such as company names or event titles.
Entity Classification
After identifying a possible entity, the system must determine its type. This is known as entity classification. Depending on the use case, categories may include names of people, organizations, locations, dates, numerical values, or even domain-specific types such as medical conditions or legal terms.
The classification process utilizes machine learning or rules to determine which category best fits the entity based on its position and the surrounding text.
Contextual Analysis
Contextual analysis adds a layer of intelligence to the process. It ensures that ambiguous entities are interpreted correctly. Take the word “Amazon,” for instance. Without context, it could refer to the river, the rainforest, or an e-commerce company.
Contextual analysis evaluates nearby words and phrases to make an informed decision. This component is especially crucial in real-world applications, where the same word may carry different meanings across various domains.
Post-processing
Finally, post-processing involves refining the results for accuracy and formatting. This step may include correcting false positives, linking detected entities to external knowledge bases, or consolidating duplicates. It ensures the final output is clean and ready for downstream applications, such as search, classification, or analytics.
Together, these concepts form the core of how NER systems read and understand language. Their strength lies in working as a pipeline — each step building on the previous to extract structured meaning from unstructured data.
Need Faster Data Processing
Our Named Entity Recognition solutions let you quickly extract names, locations, and other key entities from complex datasets.
Benefits of Using NER
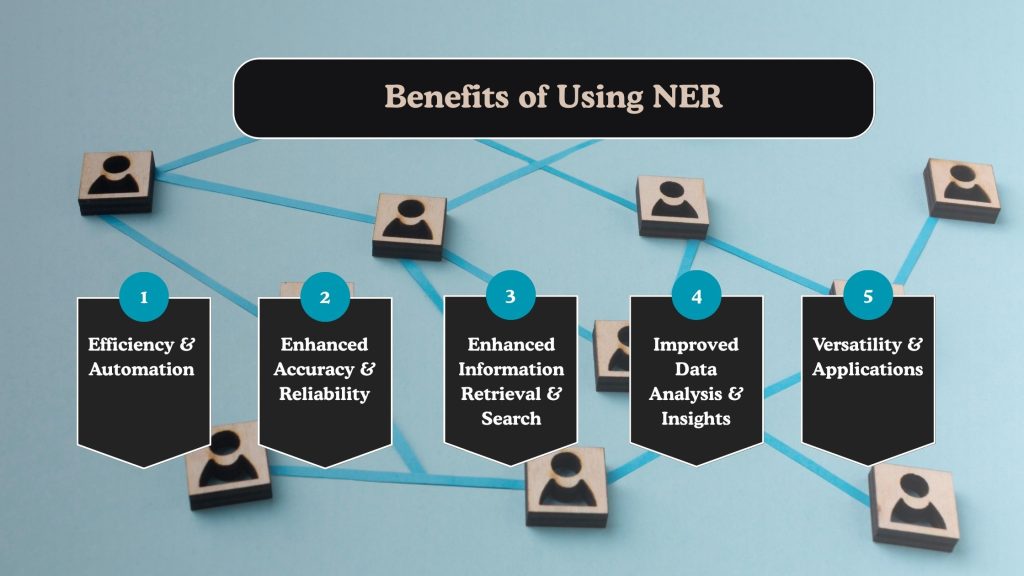
Implementing Named Entity Recognition in business workflows or data pipelines offers significant value. It enables systems to move beyond simple text handling and toward intelligent language understanding. Whether you’re dealing with customer feedback, news reports, financial records, or biomedical literature, NER enhances the way that information is processed and utilized.
Efficiency and Automation
One of the primary benefits of NER is that it significantly reduces the need for manual data extraction. Rather than having teams sift through endless documents or messages to identify key information, NER can automate this process in real-time. This leads to quicker insights and streamlined operations, particularly in industries such as finance, law, and media, where time is of the essence.
Enhanced Accuracy and Reliability
Manual tagging of entities can lead to inconsistencies and human errors. NER systems, particularly those based on machine learning, are designed to maintain consistent accuracy across large volumes of text. This reliability becomes essential when handling sensitive information, such as patient records or legal documents, where even minor errors can have severe consequences.
Enhanced Information Retrieval and Search
By tagging entities, NER systems improve the quality and relevance of search results. Instead of performing basic keyword matches, search engines equipped with NER can understand intent and surface content based on entity relationships.
For example, searching for “AI in retail” might return content specifically related to technologies used by well-known retail companies, even if the exact phrase wasn’t used.
Improved Data Analysis and Insights
NER turns unstructured text into structured data, making it easier to analyze. Organizations can track trends, sentiment, and behavior based on how often and in what context certain entities are mentioned. This is particularly helpful in social media analysis, market research, and competitive intelligence, where large amounts of textual data need to be mined for insight.
Versatility and Applications
Another major advantage of NER is its broad applicability across sectors. Whether it’s filtering resumes in HR systems, tagging diseases in medical reports, or identifying financial instruments in earnings calls, NER can be customized for different domains. Its ability to adapt to various data types and business contexts makes it a foundational tool for modern NLP applications.
You Might Also Like
Use Cases of Named Entity Recognition

Named Entity Recognition plays a crucial role in real-world applications across various industries. By transforming unstructured text into structured information, it unlocks powerful opportunities for automation, informed decision-making, and enhanced user engagement. Below are key use cases where NER is actively delivering value:
Categorizing Documents
Organizations often need to manage vast amounts of documents, ranging from contracts and reports to customer feedback and research papers. NER helps categorize these documents by extracting key entities, such as dates, client names, project titles, or legal terms. This improves both document organization and retrieval, enabling smarter filtering and indexing.
Smart Contract Risk Detection
In industries such as finance and insurance, NER is used to review contracts and identify potential risks. By identifying key clauses, dates, party names, or financial terms, it becomes easier to detect anomalies or missing elements.
Tools such as Gramener’s SCRI (Smart Contract Risk Identifier) demonstrate how NER can automate risk analysis in legal and regulatory documentation.
Customer Service Support
NER is integrated into customer service platforms to extract meaningful details from user queries and support tickets.
For example, it can detect product names, user complaints, or reference IDs in a message, helping agents or chatbots respond more accurately. This not only speeds up resolution but also personalizes the customer experience.
Sentiment Insights from Feedback
When paired with sentiment analysis, NER enables businesses to track how specific entities— such as brands, products, or service categories—are perceived by customers. By identifying and tagging these entities in reviews, social media posts, or surveys, companies can gain detailed feedback at scale and act more quickly on brand perception and customer satisfaction.
Healthcare & Biomedical Use
In healthcare, NER is used to extract patient details, symptoms, drug names, and medical conditions from clinical notes, prescriptions, and reports. This accelerates diagnostics, aids in patient profiling, and ensures better data structuring in electronic health records.
NER also supports biomedical research by tagging gene names, protein structures, and diseases in research papers.
Powering Recommendations
NER contributes to more relevant recommendation engines by identifying and classifying entities in user behavior data. For instance, in e-commerce, recognizing brand names, product types, or categories from past purchases or browsing history allows systems to suggest products that better match user preferences.
Media Content Tagging
NER is widely used in the media industry to automatically tag content with people, organizations, and event names. This metadata enhances searchability, helps organize archives, and powers related content recommendations. News platforms, blogs, and media outlets rely on such tagging to deliver contextual and personalized user experiences.
Resume Filtering
Recruitment platforms utilize NER to scan resumes and extract critical data, including names, job titles, skills, certifications, and company names. By structuring this information, recruiters can match candidates to roles more efficiently, filter out irrelevant profiles, and improve overall hiring speed and accuracy.
Smarter Chatbots
NER enables chatbots to identify specific entities in user inputs, such as names, product codes, addresses, or booking dates. This enables the bot to better understand queries, personalize responses, and perform tasks such as tracking orders, scheduling appointments, or answering FAQs in a more human-like manner.
You Might Also Like
Search Engine Enhancement
Search engines leverage NER to deliver more relevant and context-aware results. Instead of relying solely on keywords, they analyze the entities within a query to understand user intent. This leads to smarter auto-suggestions, filters, and better precision in displaying results, whether in web search, knowledge bases, or enterprise tools.
What is the Purpose of Named Entity Recognition?
The primary purpose of Named Entity Recognition is to bridge the gap between unstructured human language and structured data that machines can process effectively. In essence, NER transforms raw text into meaningful, categorized information, enabling software systems to understand and act on it.
One of its core objectives is to make vast amounts of textual data searchable, analyzable, and usable for different applications. Whether it’s extracting company names from financial news, identifying drug mentions in medical reports, or detecting product references in customer feedback, NER helps reveal critical insights that might otherwise remain hidden in plain text.
Another important purpose is to enhance automation and reduce manual intervention in data-heavy workflows. By accurately detecting and classifying entities, NER enables businesses to enhance efficiency, minimize human errors, and gain faster access to the information they need.
Ultimately, the goal of NER is not just about recognizing names or terms — it’s about enabling smarter decision-making, improving information retrieval, and powering intelligent systems that can interact with human language in a meaningful way.
The Future of NER
The future of Named Entity Recognition is closely tied to the rapid advancements in natural language processing, machine learning, and large language models. As these technologies continue to evolve, NER systems are becoming more context-aware, multilingual, and adaptable to specialized domains.
One of the biggest trends shaping the future is the integration of deep learning and transformer-based architectures, such as BERT, RoBERTa, and GPT-based models. These models excel at capturing context, enabling NER to handle ambiguous terms, slang, and nuanced language far better than traditional methods. This results in greater accuracy in real-world applications, ranging from customer service automation to biomedical research.
Another emerging area is domain-specific NER, where models are trained on specialized datasets to perform exceptionally well in industries like healthcare, finance, and legal services. This targeted approach ensures that unique terminology and entity types are recognized with higher precision.
Additionally, the combination of NER with other NLP techniques, such as sentiment analysis, relation extraction, and knowledge graph construction, is expected to create even richer insights from text. For example, businesses will not only know which entities are mentioned but also how they are connected and perceived.
With the rise of multilingual models, future NER systems will also handle cross-lingual entity recognition more efficiently, breaking down barriers for global communication and analysis.
As AI systems become more integrated into everyday workflows, NER will remain a foundational tool for extracting meaning from unstructured content, only becoming faster, smarter, and more accurate with time.
Ready to Make Your Data Work Smarter?
Named Entity Recognition helps you automatically detect and classify important entities, boosting accuracy and efficiency in your workflows.
Conclusion
Named Entity Recognition has evolved into a vital technology for extracting structured insights from unstructured text, powering applications across industries from search engines to compliance systems. With continuous advancements in machine learning and natural language processing, NER systems are becoming more accurate, context-aware, and domain-adaptable.
As organizations increasingly rely on automated text understanding, NER will remain a cornerstone for enhancing decision-making, streamlining workflows, and unlocking the true potential of data-driven solutions.
At BigDataCentric, we go beyond offering generic solutions — we deliver custom-built, intelligent, and scalable NER systems designed to meet the unique demands of various industries. By combining our expertise in data science, machine learning, and advanced analytics, we help businesses transform vast amounts of raw, unstructured data into accurate, actionable intelligence.
Our goal is to empower organizations to make faster, smarter decisions, boost operational efficiency, and achieve measurable growth through truly data-driven strategies.
FAQs
-
Can NER detect emotions or sentiments?
No, NER focuses on identifying and classifying entities like names, dates, and locations. Emotion or sentiment detection is handled by separate sentiment analysis techniques.
-
How does NER differ from other Natural Language Processing techniques?
NER specifically extracts and categorizes named entities, while other NLP techniques may focus on tasks like translation, summarization, sentiment analysis, or topic modeling.
-
Can NER work with real-time data streams?
Yes, with optimized models and streaming pipelines, NER can process text from real-time sources such as chatbots, social media feeds, or live news.
-
What is zero-shot Named Entity Recognition?
Zero-shot Named Entity Recognition is an approach where a model can identify and classify entities without having seen labeled training examples for those specific entity types. It relies on general language understanding and prompts or descriptions of the entity categories, making it useful for new or domain-specific tasks without retraining.

Jayanti Katariya is the CEO of BigDataCentric, a leading provider of AI, machine learning, data science, and business intelligence solutions. With 18+ years of industry experience, he has been at the forefront of helping businesses unlock growth through data-driven insights. Passionate about developing creative technology solutions from a young age, he pursued an engineering degree to further this interest. Under his leadership, BigDataCentric delivers tailored AI and analytics solutions to optimize business processes. His expertise drives innovation in data science, enabling organizations to make smarter, data-backed decisions.




