How to Optimize ETL Processes Efficiently?

 Total View: 62
Total View: 62
Submitting the form below will ensure a prompt response from us.
As organizations handle increasing volumes of data, ETL (Extract, Transform, Load) pipelines can become slow, inefficient, and costly. This raises an important question: how can you improve ETL performance?
The answer lies in ETL process optimization—a set of strategies and techniques used to enhance the speed, scalability, and reliability of data pipelines.
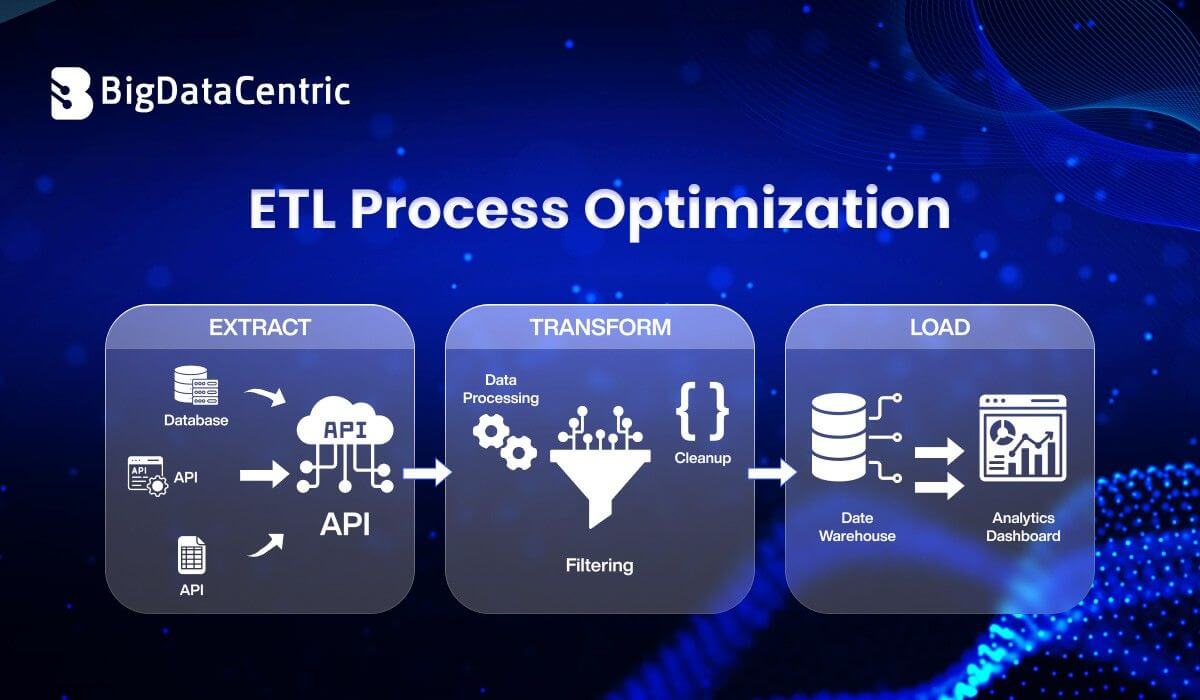
What is ETL Process Optimization?
ETL process optimization refers to improving the efficiency of data extraction, transformation, and loading workflows by:
- Reducing processing time
- Minimizing resource usage
- Improving data quality
- Ensuring scalability
It ensures that data pipelines can handle growing data volumes without performance degradation.
Why is ETL Optimization Important?
Without optimization, ETL pipelines may suffer from:
- Slow data processing
- High infrastructure costs
- Data bottlenecks
- Delayed analytics
- Poor system performance
Optimized ETL pipelines enable:
- Faster insights
- Real-time analytics
- Better resource utilization
Key Areas of ETL Optimization
Optimize Data Extraction
Efficient extraction reduces load on source systems.
Best practices:
- Use incremental data extraction
- Filter unnecessary data
- Avoid full table scans
Python Example: Incremental Extraction
import pandas as pd
# Simulated data
data = pd.DataFrame({
"id": [1, 2, 3, 4],
"updated_at": ["2024-01-01", "2024-02-01", "2024-03-01", "2024-04-01"]
})
# Extract only recent records
last_run = "2024-02-01"
filtered_data = data[data["updated_at"] > last_run]
print(filtered_data)
Optimize Data Transformation
Transformation is often the most resource-intensive step.
Strategies:
- Use efficient algorithms
- Avoid redundant transformations
- Use vectorized operations (e.g., Pandas, Spark)
Python Example: Vectorized Transformation
import pandas as pd
df = pd.DataFrame({"sales": [100, 200, 300]})
# Efficient transformation
df["tax"] = df["sales"] * 0.1
print(df)
Optimize Data Loading
Loading large datasets can cause bottlenecks.
Best practices:
- Use bulk inserts
- Partition tables
- Use parallel loading
Python Example: Batch Insert Simulation
def batch_insert(data, batch_size=2):
for i in range(0, len(data), batch_size):
batch = data[i:i+batch_size]
print("Inserting batch:", batch)
data = [1, 2, 3, 4, 5]
batch_insert(data)
You Might Also Like
Business Analytics as a Service Explained for Enterprise Growth
Advanced ETL Optimization Techniques
Parallel Processing
Run multiple ETL tasks simultaneously to reduce execution time.
Data Partitioning
Split large datasets into smaller chunks for faster processing.
Indexing
Improve query performance during transformation and loading.
Caching
Store intermediate results to avoid recomputation.
Pushdown Optimization
Let the database handle transformations instead of the ETL tool.
ETL Optimization Strategies
| Strategy | Focus Area | Benefit |
|---|---|---|
| Incremental Load | Data Extraction | Reduces data volume |
| Parallel Execution | Processing | Speeds up processing |
| Partitioning | Data Handling | Improves scalability |
| Indexing | Query Performance | Faster queries |
| Compression | Storage | Saves storage |
ETL vs ELT Optimization
| Aspect | ETL | ELT |
|---|---|---|
| Transformation | Before load | After load |
| Performance | Limited | High (cloud-based) |
| Flexibility | Lower | Higher |
Modern architectures often prefer ELT for scalability.
Common ETL Bottlenecks
- Large data volumes
- Inefficient queries
- Network latency
- Poor schema design
- Lack of parallelism
Identifying bottlenecks is key to optimization.
Security Considerations
- Encrypt sensitive data
- Use secure data transfer protocols
- Implement access controls
- Mask sensitive information
Future Trends in ETL Optimization
- AI-driven pipeline optimization
- Real-time streaming ETL
- Serverless data pipelines
- Data lakehouse architectures
- Automated data quality checks
Build Scalable Data Systems
Design high-performance ETL workflows for modern data architectures.
Conclusion
ETL process optimization is essential for building high-performance data pipelines in modern data environments.
By applying strategies like:
- Incremental loading
- Parallel processing
- Efficient transformations
- Batch loading
Organizations can significantly improve performance, reduce costs, and enable faster decision-making.
Optimized ETL pipelines are the backbone of scalable and efficient data systems.

Jayanti Katariya is the CEO of BigDataCentric, a leading provider of AI, machine learning, data science, and business intelligence solutions. With 18+ years of industry experience, he has been at the forefront of helping businesses unlock growth through data-driven insights. Passionate about developing creative technology solutions from a young age, he pursued an engineering degree to further this interest. Under his leadership, BigDataCentric delivers tailored AI and analytics solutions to optimize business processes. His expertise drives innovation in data science, enabling organizations to make smarter, data-backed decisions.













