
Data Science Vs. Machine Learning: Unveiling the Core Differences

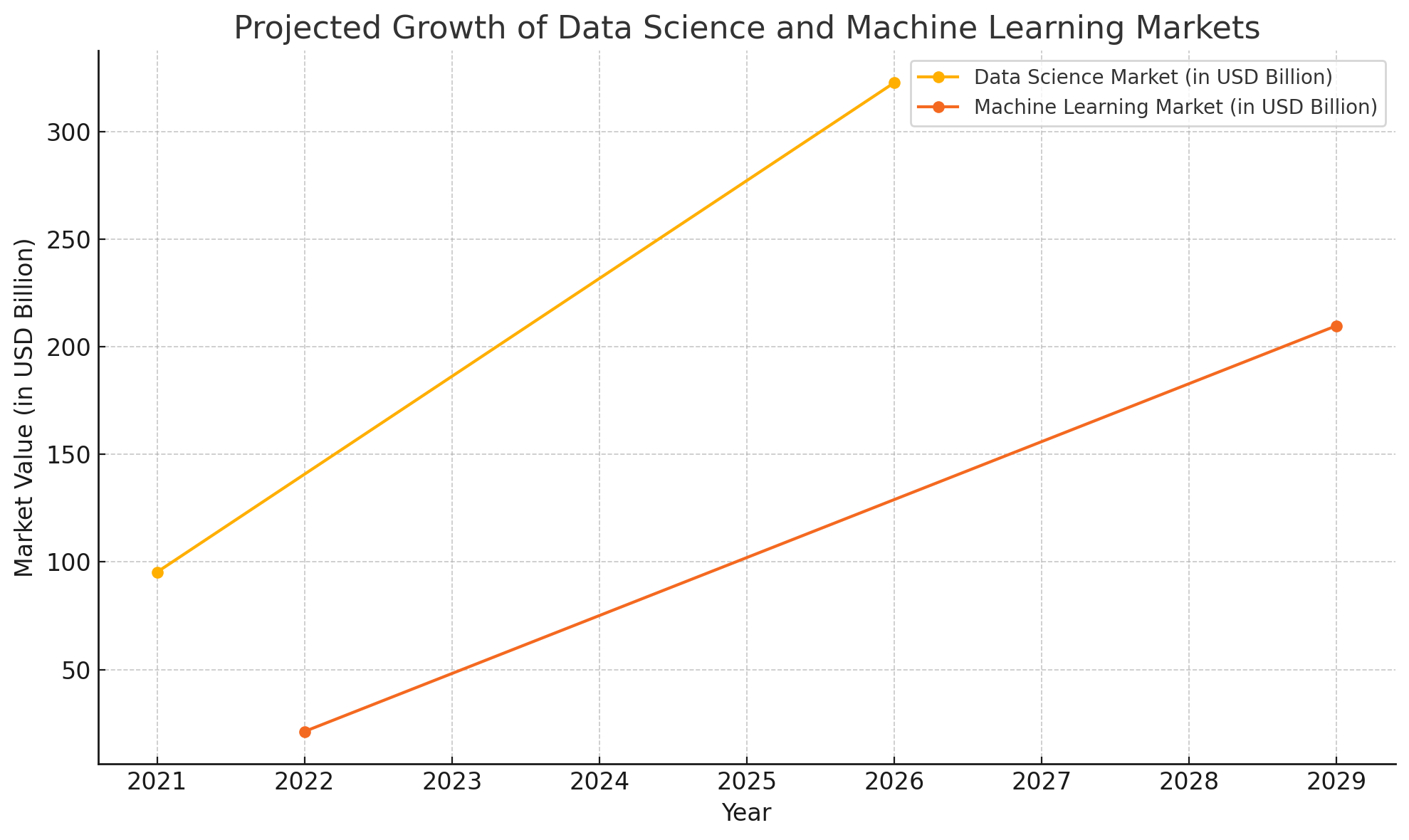
The global Data Science platform market is projected to grow from USD 95.3 billion in 2021 to USD 322.9 billion by 2026. Similarly, the Machine Learning market is expected to rise from USD 21.17 billion in 2022 to USD 209.91 billion by 2029. Companies using these technologies effectively see significant benefits, including 8% higher revenue growth and 10% higher operating margins. The demand for professionals in these fields is also surging, with roles like Data Scientist and Machine Learning Engineer among the top emerging jobs.
In today’s rapidly evolving technology landscape, understanding the nuances between “Data Science vs. Machine Learning” is essential. Data Science, encompassing statistical analysis, machine learning, and data mining, plays a crucial role in extracting meaningful insights from vast datasets.
It empowers businesses to make informed decisions, enhance operational efficiency, and personalize customer experiences. On the other hand, Machine Learning focuses on developing algorithms that enable systems to learn and improve from data without explicit programming. This capability drives innovations such as autonomous vehicles, personalized recommendations, and predictive analytics. Together, Data Science and Machine
Learning forms the backbone of artificial intelligence, revolutionizing industries ranging from healthcare and finance to retail and beyond. Their combined impact underscores their pivotal role in shaping the future of technology and data-driven decision-making.
What is Data Science?
Data Science is a multidisciplinary field that utilizes scientific methods, algorithms, processes, and systems to extract knowledge and insights from structured and unstructured data. It combines elements of mathematics, statistics, computer science, and domain expertise to interpret and analyze complex data sets. The primary goal of data science is to uncover patterns, trends, and correlations that can be used to inform business decisions, optimize processes, and solve complex problems.
Key Components of Data Science
- Data Collection: Gathering relevant data from various sources, including databases, APIs, and sensors.
- Data Cleaning and Preprocessing: Ensuring data quality by handling missing values, removing duplicates, and transforming data into a usable format.
- Exploratory Data Analysis (EDA): Analyzing data using statistical graphics and summary statistics to uncover patterns and relationships.
- Statistical Modeling: Applying statistical techniques such as regression analysis, hypothesis testing, and clustering to understand data and make predictions.
- Machine Learning: Developing and deploying machine learning models to automate predictive analytics and gain deeper insights from data.
- Data Visualization: Creating visual representations of data using charts, graphs, and dashboards to communicate findings effectively.
Applications of Data Science
- Finance: Predicting market trends, detecting fraud, and optimizing investment portfolios.
- Healthcare: Analyzing patient data for personalized medicine, predicting disease outbreaks, and improving treatment outcomes.
- E-commerce: Recommending products to customers based on their preferences and behavior.
- Manufacturing: Optimizing production processes, predicting equipment failures, and ensuring quality control.
- Marketing: Targeting specific customer segments, optimizing advertising campaigns, and measuring campaign effectiveness.
- Transportation: Analyzing traffic patterns, optimizing routes, and developing autonomous vehicle systems.
Data Science Process
Problem Definition
This initial step involves clearly understanding and articulating the business problem or research question. Close collaboration with stakeholders is required to identify the objectives and desired outcomes. Defining the problem accurately sets the direction for the entire data science project.
Data Collection
This involves gathering data from various sources, which can include databases, APIs, web scraping, or external datasets. Ensuring the data is comprehensive and relevant is crucial for accurate analysis. Proper documentation of data sources and collection methods is also important.
Data Cleaning and Preprocessing
In this step, raw data is cleaned to remove errors, inconsistencies, or missing values. Then, it is transformed into a suitable format for analysis, which might involve normalization, scaling, or encoding categorical variables. This step ensures the data’s quality and reliability.
Exploratory Data Analysis
EDA involves using statistical and visualization techniques to understand the data’s underlying patterns, distributions, and relationships. It helps identify trends, outliers, and potential anomalies, providing insights that inform the subsequent steps in the data science process.
Feature Engineering
This step focuses on creating new features or selecting existing ones that are most relevant to the problem. Feature engineering enhances the predictive power of machine learning models by transforming raw data into meaningful attributes.
Model Selection and Training
Different machine learning algorithms are evaluated to determine which is most suitable for the task. Models are trained using historical data, with techniques such as cross-validation to ensure robustness. This step involves iterating through various models and parameters to optimize performance.
Evaluation
The trained models are assessed using various metrics, such as accuracy, precision, recall, F1-score, and ROC-AUC. Evaluation helps validate the model’s performance and ensure it meets the desired criteria. This step also involves comparing different models to select the best one.
Deployment
Once a model is finalized, it is deployed into production systems where it can make real-time predictions. Continuous monitoring of the model’s performance is essential to ensure it operates effectively and adapts to any changes in data patterns over time.
What is Machine Learning?
Machine Learning is a subset of artificial intelligence (AI) that focuses on enabling machines to learn from data and improve their performance over time without being explicitly programmed. The primary Goal of machine learning is to develop algorithms and models that can automatically learn and make decisions based on patterns and insights derived from data.
Key Components of Machine Learning:
- Supervised Learning: Involves training models on labeled data to predict outcomes for new data points. It includes regression (predicting continuous values) and classification (predicting categories).
- Unsupervised Learning involves training models on unlabeled data to discover patterns and structures within it. It includes clustering (grouping similar data points) and association (identifying relationships among data).
- Reinforcement Learning: It involves training models to make sequences of decisions by rewarding desired behaviors and punishing undesired ones. It is often used in applications like game playing and robotics.
- Deep Learning: A subset of machine learning that uses neural networks with multiple layers to learn hierarchical representations of data. It is particularly effective for tasks such as image recognition, speech recognition, and natural language processing.
Applications of Machine Learning:
Machine learning finds applications across various industries and domains, including:
- Healthcare: Diagnosing diseases from medical images, predicting patient outcomes, and personalizing treatment plans.
- Finance: Detecting fraud in financial transactions, forecasting stock prices, and credit scoring.
- E-commerce: Recommending products to customers based on their preferences and purchase history.
- Marketing: Targeting advertisements to specific customer segments and predicting customer churn.
- Automotive: Developing autonomous vehicles capable of navigating and making decisions in real-time environments.
- Natural Language Processing (NLP): Understanding and generating human language, enabling chatbots and language translation.
Machine Learning Process
The machine learning process typically involves the following steps:
Problem Definition
The first step is to clearly define the problem that needs to be solved using machine learning. This involves understanding the business objectives and identifying how machine learning can help achieve those goals. Collaboration with stakeholders is crucial to outline the scope, constraints, and success criteria for the project.
Data Collection
Gather relevant data from various sources, such as internal databases, APIs, or external datasets. The quality and relevance of the data are critical for building effective machine-learning models. Proper documentation of the data collection process ensures transparency and reproducibility.
Data Cleaning and Preprocessing
Prepare the data for analysis by cleaning and transforming it. This step includes handling missing values, removing duplicates, correcting errors, and converting data into a suitable format. Techniques like normalization, standardization, and encoding categorical variables are often used to ensure data quality.
Exploratory Data Analysis (EDA)
Conduct EDA to gain insights into the data’s structure and characteristics. Use statistical methods and visualization tools to identify patterns, trends, and relationships in the data. EDA helps uncover any anomalies or outliers that might affect the model’s performance.
Model Evaluation
Assess the trained models using various performance metrics such as accuracy, precision, recall, F1-score, and ROC-AUC. Model evaluation helps determine how well the models generalize to unseen data. Compare different models to select the one that best meets the defined criteria.
Model Deployment
Deploy the final model into production to make real-time predictions. Implement monitoring systems to track the model’s performance and detect any issues. Continuous monitoring and maintenance are essential to ensure the model remains effective over time and adapts to changing data patterns.
Tabular Comparison of Data Science Vs. Machine Learning
| Aspect | Data Science | Machine Learning |
|---|---|---|
| Definition | Extracting insights and knowledge from data | Developing algorithms that learn from data |
| Primary Goal | Extract actionable insights and solve complex problems | Create predictive models and automate decision-making |
| Key Techniques | Statistical analysis, data mining, machine learning | Supervised, unsupervised, and reinforcement learning |
| Data Requirements | Uses both structured and unstructured data | Depends on data type (structured or unstructured) |
| Applications | Predictive analytics, customer segmentation, NLP | Image recognition, speech recognition, recommendation systems |
| Process | Data collection, cleaning, analysis, interpretation, data exploration | Data preprocessing, model training, evaluation, model evaluation |
| Focus | Interpreting data to inform decisions | Building models to predict and decide |
| Tools | R, Python, SQL, Tableau, Power BI, Spark | TensorFlow, sci-kit-learn, Keras, Decision Trees |
| Examples | Analyzing sales data to optimize marketing strategies | Developing models to classify images |
| Skills Required | Statistics, programming, domain knowledge | Algorithm development, model optimization |
| Output | Insights, visualizations, reports | Predictions, classifications, recommendations |
Data Science Vs Machine Learning: Core Differences
In the realm of modern technology, the distinctions between Data Science vs. Machine Learning are crucial for understanding their unique contributions to data-driven decision-making and automation. Here are the core differences in scope, skill sets, tools, objectives, and workflows:
Scope and Focus
Data Science:
- Scope: Data Science encompasses a broad range of activities aimed at extracting insights from data. It involves data collection, cleaning, analysis, visualization, and interpretation.
- Focus: The primary focus of data science is to uncover patterns, trends, and relationships within data to inform business decisions and strategies.
Machine Learning:
- Scope: Machine Learning is a subset of data science that specifically deals with developing algorithms capable of learning from and making predictions on data.
- Focus: The focus of machine learning is to create models that can generalize from historical data to make accurate predictions or decisions without being explicitly programmed for specific tasks.
Skill Sets and Techniques
Data Science:
- Skill Sets: Data Scientists need proficiency in statistics, programming (Python, R), data manipulation (SQL), and domain expertise. They must also be skilled in data visualization and communication.
- Techniques: Data scientists use techniques like statistical analysis, hypothesis testing, data mining, and exploratory data analysis (EDA).
Machine Learning:
- Skill Sets: Machine Learning Engineers require a strong foundation in mathematics, particularly linear algebra, calculus, and probability. They need expertise in machine learning algorithms, programming (Python, TensorFlow, sci-kit-learn), and model evaluation.
- Techniques: Techniques include supervised Learning, unsupervised Learning, reinforcement learning, and deep Learning.
Tools and Technologies
Data Science:
- Tools: Data Science utilizes tools such as R, Python, SQL, Hadoop, Spark, and data visualization tools like Tableau and Matplotlib.
- Technologies: Technologies used in data science services include big data platforms, cloud computing (AWS, Google Cloud), and various statistical software packages.
Machine Learning:
- Tools: Machine Learning relies on tools like TensorFlow, Keras, PyTorch, sci-kit-learn, and Jupyter notebooks for model development and deployment.
- Technologies: Technologies include neural networks, GPU computing, AutoML, and cloud-based machine learning services.
Focus and Objectives
Data Science:
- Focus: The focus is on interpreting data to derive actionable insights and inform strategic decisions.
- Objectives: Objectives include identifying trends, optimizing processes, and supporting decision-making through data-driven insights.
Machine Learning:
- Focus: The focus is on building and refining models to predict outcomes and automate decision-making processes.
- Objectives: Objectives include developing accurate predictive models, enhancing automation, and improving systems through continuous Learning.
Workflow and Methodology
Data Science:
- Workflow: The data science workflow involves problem definition, data collection, data cleaning, exploratory data analysis, model building, and result communication.
- Methodology: The methodology emphasizes understanding the data and its context, applying statistical techniques, and visualizing results to communicate findings effectively.
Machine Learning:
- Workflow: The machine learning workflow includes data preprocessing, feature engineering, model selection, training, validation, and deployment.
- Methodology: The methodology focuses on iterative experimentation, model optimization, and evaluation to ensure high performance and generalization.
The Trends of Data Science Vs. Machine Learning
Choosing between Data Science Vs Machine Learning depends on the specific needs and goals of an organization. Data Science is ideal for extracting insights and informing strategic decisions, while Machine Learning excels at automating processes and making accurate predictions. Both fields are essential and complementary, and their combined use often leads to the best outcomes.
Unlock Insights into Data Science Trends and Future Predictions
Discover how BigDataCentric leverages the power of Data Science and Machine Learning to revolutionize your business.
Start Your Journey Today
Conclusion
In conclusion, while Data Science focuses on extracting insights and patterns from data through statistical analysis and domain expertise, Machine Learning delves into developing algorithms that can learn and make predictions autonomously. At BigDataCentric, integrating both fields maximizes innovation and operational efficiency, harnessing their synergies for comprehensive data-driven solutions.
FAQs
-
Do Machine Learning roles pay more than Data Science?
Generally, Machine Learning roles can offer higher salaries due to specialized skills and demand, but it varies by location and experience.
-
Can you go from data science to machine learning?
Yes, transitioning from Data Science to Machine Learning is common. A strong foundation in Data Science provides the necessary skills in statistics, programming, and data analysis to excel in Machine Learning.
-
Is data science hard for non-IT students?
Data Science can be challenging for non-IT students due to the need for programming, statistical analysis, and data manipulation skills. However, with dedication, the right resources, and consistent practice, non-IT students can successfully learn and excel in Data Science.

Jayanti Katariya is the CEO of BigDataCentric, a leading provider of AI, machine learning, data science, and business intelligence solutions. With 18+ years of industry experience, he has been at the forefront of helping businesses unlock growth through data-driven insights. Passionate about developing creative technology solutions from a young age, he pursued an engineering degree to further this interest. Under his leadership, BigDataCentric delivers tailored AI and analytics solutions to optimize business processes. His expertise drives innovation in data science, enabling organizations to make smarter, data-backed decisions.




