
A Comprehensive Guide to Big Data Architecture

Blog Summary:
Mastering Big Data Architecture is crucial for leveraging data’s full potential. This comprehensive guide delves into the intricacies of Big Data Architecture, covering its components, best practices, and implementation strategies, ensuring you harness the power of big data effectively in your organization.
In today’s data-driven world, Big Data Architecture has become a critical component for businesses aiming to harness the power of vast amounts of data. By 2025, it is estimated that the global data sphere will grow to 175 zettabytes, highlighting the increasing importance of effective data management and analysis.
Companies that implement robust big data strategies can gain a competitive edge. 79% of organizations already use big data analytics to improve decision-making and operational efficiency. Understanding the nuances of Big Data Architecture is essential for leveraging its full potential and ensuring seamless data integration, storage, and analysis.
What is Big Data Architecture?
Big Data Architecture refers to the structural design and arrangement of systems that manage and process vast amounts of data. It encompasses the frameworks, methodologies, and infrastructures required to handle the complexities of storing, processing, and analyzing large datasets.
Big Data Architecture aims to ensure scalability, reliability, and efficiency in managing diverse types of data, ranging from structured to unstructured formats. By defining how data is collected, stored, and accessed, Big Data Architecture forms the foundation for organizations to derive actionable insights and make informed decisions from their data assets.
What are the 3 Types of Big Data?
In the realm of Big Data Architecture, understanding the types of big data is crucial for designing effective data systems. Big data is generally categorized into three types:
Structured Data
Definition: Structured data is highly organized and easily searchable in relational databases.
Examples: Examples include SQL databases, spreadsheets, and data tables.
Usage: This type of data is used in scenarios requiring transactional data processing and analytics, such as financial records, customer information, and inventory management.
Unstructured Data
Definition: Unstructured data lacks a predefined format, making it more complex to analyze.
Examples: Examples include text files, emails, social media posts, and multimedia files like images and videos.
Usage: It is prevalent in content management, social media analysis, and sentiment analysis due to its varied and rich information content.
Semi-Structured Data
Definition: Semi-structured data does not conform to a rigid structure but contains tags and markers to separate data elements.
Examples: Examples include JSON files, XML files, and NoSQL databases.
Usage: This type of data is often used in web data extraction and data integration tasks and for storage solutions that require flexibility, like cloud storage and big data applications.
Understanding these types of big data is essential for crafting robust and efficient Big Data Architectures that can handle diverse data sources and types.
What Are the Types of Big Data Architecture?
Big Data Architecture comes in various types to support data processing and analysis at scale. Each architecture type serves unique business needs, enabling efficient data handling and insights. Here are some big data architecture –
Lambda Architecture
Lambda Architecture is designed to handle massive quantities of data by taking advantage of both batch and stream-processing methods. It provides:
- Batch Layer: Processes large amounts of historical data and produces batch views.
- Speed Layer: Processes real-time data and creates real-time views.
- Serving Layer: Merges batch and real-time views to provide a comprehensive view.
This architecture ensures low latency, fault tolerance, and scalability, making it suitable for applications requiring real-time insights and historical data analysis.
Kappa Architecture
Kappa Architecture simplifies the Lambda approach by removing the batch layer and focusing solely on stream processing. It is ideal for applications where real-time data processing is crucial. The key features include:
- Stream Processing Engine: Handles data ingestion and processing in real time.
- Immutable Log: Stores data streams for replay and reprocessing if necessary.
This architecture is preferred when the system needs to adapt quickly to changes and provide real-time analytics without the complexity of managing both batch and stream layers.
Batch Processing Architecture
Batch Processing Architecture deals with large volumes of data collected over a period. It processes the data in batches and is well-suited for scenarios where real-time processing is not critical. Key characteristics include:
- Batch Jobs: Scheduled to run at specific intervals, processing large datasets.
- Data Storage: Utilizes data warehouses or data lakes for storing processed data.
- Cost-Effective: Optimized for throughput rather than latency, making it cost-effective for non-time-sensitive applications.
This architecture is commonly used in financial reporting, data warehousing, and other applications where the timely processing of large datasets is more important than real-time insights.
Understanding these types of Big Data Architecture is crucial for designing systems that efficiently handle the scale and complexity of big data. Each architecture has its own strengths and is suited to different use cases, ensuring that there is a solution for various data processing needs.
Components of Big Data Architecture
Big Data architecture is essential for organizations looking to harness the power of large datasets. It involves several key components, each playing a vital role in managing and analyzing data efficiently with data science. Below, we will explore these components in detail –

Data Sources
Data sources are the origin points from which data is collected, encompassing a wide range of formats and origins. Structured data, such as databases and spreadsheets, follows a predefined model and is easily searchable, making it straightforward to analyze and manipulate.
On the other hand, unstructured data, including text files, social media posts, emails, images, and videos, lacks a predefined model and requires advanced tools for processing and analysis. Semi-structured data, like JSON and XML files, falls between these two categories, containing tags or markers that separate data elements without conforming to traditional database structures.
Additionally, sensor data generated from IoT devices and industrial machines plays a crucial role in real-time monitoring and predictive maintenance. Public data, often available from government databases, academic research, and other open sources, provides valuable information for various analytical purposes.
Data Ingestion
Data ingestion refers to the process of importing and processing data from various sources into a storage system. This process can be executed through batch processing, where data is collected over a period and processed in batches, or stream processing, which involves real-time data processing as it comes in.
Batch processing is suitable for handling large volumes of data at specific intervals, making it ideal for end-of-day reporting and analytics. Conversely, stream processing is essential for applications requiring immediate data insights, such as fraud detection and real-time analytics.
Data Storage
Once data is ingested, it needs to be stored efficiently to ensure quick access and analysis. Data lakes, which store raw data in its native format, are ideal for handling vast amounts of unstructured and semi-structured data.
Data warehouses, on the other hand, store structured data and are optimized for fast querying and analysis, making them suitable for business intelligence and reporting. NoSQL databases offer flexibility in handling unstructured and semi-structured data, supporting various data models such as key-value, document, and graph formats.
Data Processing
Data processing transforms raw data into meaningful insights through methods such as ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform). ETL is a traditional method where data is extracted from source systems, transformed into a suitable format, and then loaded into a data warehouse.
This approach is effective for structured data with well-defined transformation rules. ELT, on the other hand, is more suitable for big data environments where data is first loaded into a data lake and then transformed as needed, leveraging the storage and processing capabilities of modern big data platforms.
Data Analysis
Data analysis involves examining processed data to extract insights and support decision-making. Descriptive analytics summarizes historical data to understand past trends and performance, while predictive analytics uses historical data to forecast future outcomes and identify potential risks and opportunities.
Prescriptive analytics goes a step further by recommending actions based on data analysis, helping organizations optimize their strategies and operations.
Data Visualization
Data visualization is the graphical representation of data, making complex information more accessible and understandable. Tools and techniques such as dashboards, charts, and graphs provide real-time data insights and help identify patterns and trends.
Geospatial visualization, which includes maps and geographic data representations, is particularly useful for analyzing location-based data and understanding regional trends.
Data Security
Data security is critical to protect sensitive information from unauthorized access and breaches. Key practices include encryption, which safeguards data at rest and in transit, and access controls, ensuring that only authorized users can access and manipulate data.
Auditing and monitoring are also essential for tracking data access and changes, helping detect and respond to unauthorized activity promptly.
Data Governance
Data governance involves managing data availability, usability, integrity, and security to ensure it meets organizational standards and regulatory requirements. Core aspects include data quality management, which ensures data is accurate and reliable, and compliance with regulations such as GDPR and CCPA.
Data stewardship assigns responsibility for data management within the organization, ensuring that data governance policies are consistently applied.
Data Integration
Data integration combines data from different sources into a unified view, enabling comprehensive analysis and reporting. Methods such as ETL and ELT integrate data during processing, while data virtualization allows real-time access to data without moving it.
API integration connects different systems and applications, facilitating seamless data sharing and enhancing the overall data ecosystem.
Data Management
Data management encompasses the practices and tools used to manage data throughout its lifecycle. Master data management (MDM) ensures consistency and accuracy of key business data, while data lifecycle management oversees data from creation to deletion.
Metadata management, which involves managing data about data, improves searchability and governance, ensuring that data is well-documented and easily accessible for analysis.
Unlock the Power of Big Data Architecture for Your Business
Discover how advanced Big Data Architecture can transform your data strategy, boost efficiency, and drive actionable insights.
Who Uses Big Data Architecture?
Big data architecture has become a crucial component for organizations seeking to leverage large datasets to gain insights and drive decision-making. Various sectors utilize big data architecture to enhance their operations, improve customer experiences, and maintain competitive edges. Here are some of the key industries that rely on big data architecture:
Financial Institutions
Financial institutions, including banks, investment firms, and insurance companies, heavily invest in big data architecture to manage vast amounts of transactional data. By leveraging big data, these institutions can:
- Detect and prevent fraud through real-time analysis of transaction patterns.
- Enhance customer experience by offering personalized financial products.
- Optimize risk management and compliance with regulatory requirements.
- Improve investment strategies by analyzing market trends and consumer behavior.
Healthcare Providers
Healthcare providers, such as hospitals, clinics, and pharmaceutical companies, use big data architecture to transform patient care and streamline operations. Key applications include:
- Predictive analytics to foresee patient outcomes and improve treatment plans.
- Efficient management of electronic health records (EHRs) for better patient data accessibility.
- Research and development of new drugs and treatments through data-driven clinical trials.
- Public health surveillance to track and manage disease outbreaks.
Retail and E-commerce Businesses
Retailers and e-commerce platforms leverage big data architecture to understand customer preferences and optimize their business processes. Benefits include:
- Personalized marketing campaigns based on customer purchase history and browsing behavior.
- Inventory management and demand forecasting to ensure stock availability.
- Price optimization by analyzing competitive pricing and market trends.
- Enhanced customer service through sentiment analysis and feedback management.
Government Agencies
Government agencies at local, state, and federal levels use big data architecture to enhance public services and policy-making. Applications include:
- Analyzing public data to improve social services and allocate resources efficiently.
- Enhancing public safety through crime pattern analysis and predictive policing.
- Monitoring and managing infrastructure projects with real-time data.
- Ensuring transparency and accountability through open data initiatives.
Travel and Hospitality Industry
The travel and hospitality industry relies on big data architecture to enhance customer experiences and operational efficiency. Notable applications are:
- Personalizing travel recommendations and offers based on customer preferences.
- Optimizing pricing strategies through dynamic pricing models.
- Managing logistics and improving supply chain efficiency for better service delivery.
- Analyzing customer feedback to improve services and maintain high satisfaction levels.
Benefits of Big Data Architecture
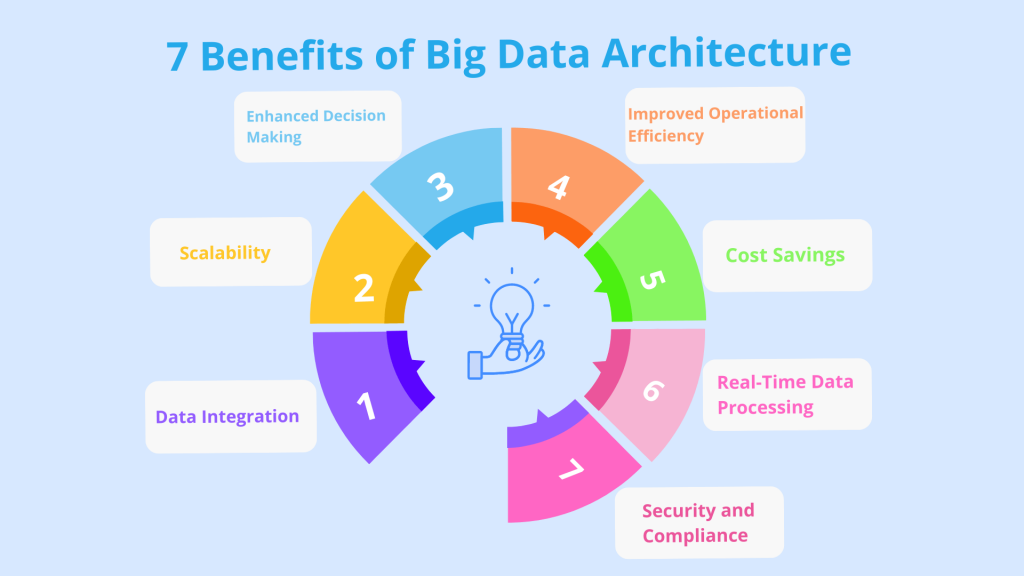
Big Data Architecture has revolutionized the way businesses handle and analyze data. With its advanced capabilities, organizations can derive meaningful insights, enhance their decision-making processes, and gain a competitive edge. Here are the key benefits of Big Data Architecture:
Enhanced Decision Making
- Data-Driven Decisions: Big Data Architecture enables organizations to make informed decisions based on data analysis rather than intuition, leading to more accurate and reliable outcomes.
- Predictive Analytics: By leveraging predictive models, businesses can forecast trends, identify potential risks, and make proactive decisions that align with future market dynamics.
Improved Operational Efficiency
- Process Optimization: Analyzing large volumes of data helps identify inefficiencies and streamline processes. This can lead to significant time and cost savings.
- Automation: Automated data processing reduces the need for manual intervention, speeding up operations and minimizing human error, thus enhancing productivity.
Scalability
- Handling Growth: Big Data Architecture is designed to scale with the increasing volume, velocity, and variety of data. It ensures that the system can handle more data without performance degradation.
- Flexible Infrastructure: It supports both horizontal and vertical scaling, allowing businesses to add more resources or upgrade existing ones as their data needs grow, ensuring seamless data management.
Cost Savings
- Resource Optimization: Efficient data management reduces storage and processing costs. By eliminating redundant data and optimizing storage, businesses can save substantial amounts.
- Cloud Integration: Leveraging cloud-based solutions minimizes the need for expensive on-premises infrastructure. This allows businesses to pay only for what they use, reducing capital expenditure.
Real-Time Data Processing
- Immediate Insights: Real-time analytics allows businesses to act on data as it is generated, leading to quicker decision-making. This can be crucial in dynamic markets where timing is everything.
- Operational Agility: It enhances the ability to respond to market changes and customer demands promptly. Businesses can adjust strategies and operations on-the-fly based on real-time data.
Data Integration
- Unified View: Big Data Architecture integrates data from various sources, providing a comprehensive view of the organization. This holistic view helps in making more informed decisions.
- Seamless Access: It ensures easy access to data across different departments, fostering collaboration. This leads to better alignment and synergy within the organization.
Security and Compliance
- Data Protection: Robust security measures protect sensitive data from breaches and cyber threats. This ensures the integrity and confidentiality of business and customer data.
- Regulatory Compliance: Ensures adherence to data protection regulations, avoiding legal issues and fines. Compliance with standards like GDPR and HIPAA builds trust with customers and partners.
Big Data Architecture not only transforms data management but also propels businesses toward innovation and growth. By leveraging its benefits, organizations can enhance their decision-making, optimize operations, and gain a competitive edge in the market.
Challenges of Big Data Architecture
In the realm of data management, Big Data Architecture plays a pivotal role in shaping how organizations process, store, and analyze massive volumes of data. Understanding the complexities and challenges associated with Big Data Architecture is crucial for leveraging its full potential.
Big data architecture presents a multitude of challenges that organizations must navigate to harness its full potential. Here are some of the key opportunities for growth and improvement:
Complexity of Data Management
Big Data Architecture excels in efficiently managing diverse data types, including structured, semi-structured, and unstructured data, transforming challenges into opportunities for innovation and seamless integration. This complexity requires robust systems for data integration, transformation, and storage across distributed environments. Effective metadata management and data governance frameworks are crucial to maintain coherence and accessibility amidst this complexity.
Data Security and Privacy
Protecting sensitive information from unauthorized access and breaches is paramount in Big Data environments. With data dispersed across multiple platforms and accessed by various stakeholders, implementing robust encryption, access controls, and compliance measures (like GDPR or CCPA) are essential. Data anonymization and regular security audits further ensure data integrity and user privacy.
Data Quality and Integrity
Maintaining high data quality is critical for meaningful analytics and decision-making. Challenges include ensuring data consistency across disparate sources, identifying and rectifying errors (such as duplicates or incomplete records), and establishing data validation processes. Implementing data profiling and cleansing tools alongside rigorous data governance practices helps maintain data integrity throughout its lifecycle.
High Costs
Investing in Big Data infrastructure, including advanced hardware, cutting-edge software, and skilled personnel, unlocks immense value and long-term benefits, making it a strategic choice for organizations aiming for transformative growth. Investments in scalable cloud solutions or distributed computing frameworks like Hadoop mitigate initial costs but require ongoing monitoring and optimization to manage expenses effectively. Cost-benefit analyses and strategic resource allocation are crucial for optimizing ROI while scaling operations.
Real-Time Data Processing
Businesses increasingly rely on real-time data insights to drive operational efficiency and competitive advantage. Challenges include processing large volumes of streaming data promptly, ensuring low-latency data delivery, and supporting complex event processing.
Implementing scalable stream processing frameworks like Apache Kafka or Apache Flink, coupled with efficient data ingestion and processing pipelines, enables timely decision-making and responsiveness to dynamic market conditions.
What are Real-world Big Data Architecture Examples?
Real-world Big Data Architecture examples include systems used by tech giants and industries to manage massive data volumes. These architectures help companies efficiently analyze and leverage big data for better decision-making and personalized user experiences.
Google’s Bigtable Architecture
Google’s Big Table is pivotal for services like Search and Maps, scaling across servers for real-time data access. Its NoSQL design handles diverse data types efficiently, supporting Google’s vast data needs.
Apache Hadoop Ecosystem
Hadoop enables distributed processing of large datasets, powering scalable storage and computation across clusters. It’s integral for organizations managing big data for analytics and insights.
Amazon Web Services (AWS) Data Lake Architecture
The AWS Data Lake allows for the storage and analysis of structured and unstructured data at scale. Integrating S3, Glue, and Athena, it supports agile data management and advanced analytics capabilities.
Netflix Real-time Stream Processing
Netflix uses Apache Kafka and Flink for real-time data processing, enhancing user experience through personalized content recommendations and operational insights.
Uber’s Michelangelo Platform
Michelangelo manages end-to-end machine learning workflows, facilitating feature management, model versioning, and scalable prediction serving for Uber’s operations and innovations.
Discover the Future of Data with Advanced Big Data Architecture
Learn how our tailored solutions can transform your data strategy into a competitive advantage.
Conclusion
The journey to mastering Big Data Architecture involves continuous learning and adaptation. As technologies evolve and data volumes grow, staying updated with the latest trends and best practices is crucial. Embracing this dynamic field opens up opportunities for innovation and significant advancements across various industries.
FAQs
-
What is the 5-layer architecture of big data?
Big Data Architecture typically consists of layers: data sources, ingestion, storage, processing, and visualization. Each layer handles specific tasks, from data collection to analysis and presentation.
-
Why is Big Data Architecture important for businesses?
Big Data Architecture enables businesses to efficiently collect, store, process, and analyze large volumes of data. This capability drives informed decision-making, enhances operational efficiency, and fosters innovation.
-
Can you provide examples of real-world applications of Big Data Architecture?
Real-world applications include personalized recommendations by Amazon, fraud detection by banks using transaction data, and predictive maintenance in manufacturing using sensor data.
-
What are the main components of big data?
The main components include data sources (like IoT devices), data storage systems (like Hadoop and NoSQL databases), data processing frameworks (like Apache Spark), and visualization tools (like Tableau).

Jayanti Katariya is the CEO of BigDataCentric, a leading provider of AI, machine learning, data science, and business intelligence solutions. With 18+ years of industry experience, he has been at the forefront of helping businesses unlock growth through data-driven insights. Passionate about developing creative technology solutions from a young age, he pursued an engineering degree to further this interest. Under his leadership, BigDataCentric delivers tailored AI and analytics solutions to optimize business processes. His expertise drives innovation in data science, enabling organizations to make smarter, data-backed decisions.




